XML-XSL технология для построения интернет сайта
|
Описываются принципы использования XML-XSL
технологии для построения
интернет-сайта, ориентированного на небольшой поток новостей (слово «небольшой»
позволяет обойтись без баз данных)
Кратко рассматривается роль составных частей технологии
– таблицы стилей CSS, XML описания страницы и XSL преобразования.
Обсуждается структура интернет сайта, ориентированного на
новости. В работе такие сайты называются новостными.
Вторая части работы посвящена XSL преобразованиям. Рассматривается их
специфика (непроцедурное программирование), приводится несколько упрощенных примеров использования XML-XSL технологии для построения интернет страниц (меню и
английская версия сайта).
Работа завершается обсуждением редакторского и отладочного
режимов – в этих режимах сайт тестируется перед внесением в него дополнений и изменений.
Планируется такое общее рассмотрение XML-XSL технологии впоследствии
сопроводить более конкретными текстами. Например, изложением деталей XML языка для описания содержания
интернет страницы.
Предполагается знакомство с основными тегами языка HTML и с понятиями XML языка и XSL преобразования.
Эта работа посвящается памяти Евгения Валентиновича
Хухлаева, с которым автору посчастливилось общаться на этапе вхождения в эту
тематику.
Автор благодарит Александра Стрелецкого (Вильнюс) и Юрия
Ревякина (ИПМ) за многочисленные обсуждения XML-XSL проблематики.
Благодарности А.В.Пурнику, М.М.Горбунову-Посадову,
Э.З.Любимскому, М.И.Слепенкову, Е.Л.Китаеву, Д.Л.Кузьмичеву.
1 Постановка задачи – содержание страницы
и ее
представление-презентация.
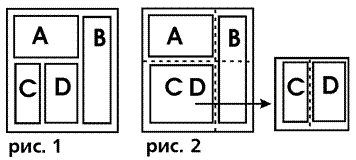
Предположим, что мы хотим сделать такую интернет страницу, как на рис.1.
Здесь A, B, C, D есть некоторые
объекты, например, просто тексты. Эти объекты могут быть и составными, в свою
очередь распадающимися на вложенные
объекты.
В языке HTML есть единственный способ управлять
местоположением объектов на странице – с помощью так называемых таблиц.
Интернет страница представляется разбитой на строки и столбцы, в ячейки такой
таблицы помещаются любые конструкции
языка HTML. Используются теги <table> (таблица),
<tr> (строка) и <td> (ячейка), есть и другие теги, связанные с таблицей. Можно
объединять несколько ячеек в одну, используя атрибуты тега <td>
rowspan и colspan. Для тегов <table> и <td> есть атрибут width – ширина таблицы и ячейки. Есть атрибуты
cellspacing, cellpadding – они задают расстояние между
ячейками и отступ от края ячейки. Можно
использовать вложенные таблицы –
ячейка таблицы может содержать другую таблицу.
В этих терминах – с помощью таблиц – страницу на рис.1 на
языке HTML можно представить как
таблицу на рис.2 слева, в которой в левой нижней ячейке содержится
другая таблица, изображенная на рис.2 справа.
Пунктирами показано разделение таблиц на ячейки. Первая таблица на языке
HTML записывается примерно так
<table>
<tr>
<td width=300>A</td>
<td
rowspan=2 width=150>B</td>
</tr>
<tr>
<td>СD</td>
</tr>
</table>
Здесь rowspan=2 означает, что ячейка объединяется с ячейкой, которая находится
ниже ее (в следующем ряду). Атрибуты width задают ширину колонок, A и B – это объекты исходной таблицы, CD означает вложенную таблицу на рис.2 справа, в ней одна строка и два столбца. Эта
вторая таблица CD записывается
примерно так
<table>
<tr>
<td width=150>C</td>
<td>D</td>
</tr>
</table>
То же самое расположение объектов можно было бы определить,
рассматривая только одну таблицу, но
состоящую из трех столбцов. Тогда для объекта A надо объединить две первые
ячейки в первой строке. Тогда HTML код
выглядел бы примерно так
<table>
<tr>
<td
colspan=2>A</td>
<td
rowspan=2 width=150>B</td>
</tr>
<tr>
<td
width=150>С</td>
<td>D</td>
</tr>
</table>
А теперь представим себе, что по какой-то причине мы хотим
изменить внешний вид страницы и ту же информацию (то же содержание) разместить
иначе, а именно так, как на рис.3.
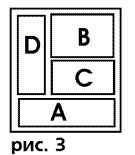
Если объекты A, B, C, D опять будут вписываться в таблицу, то структура этой новой
таблицы будет совсем другая, объединяться будут другие ячейки. К тому же первым теперь стал объект D. Изменить предыдущее HTML описание страницы для того, чтобы получить новое расположение
объектов на странице, будет достаточно трудоемко, особенно учитывая то, что
объекты A, B, C, D обычно представляют собой тоже некоторые куски кода HTML (быть может, содержащие свои теги
<table>, <tr> и <td>).
Здесь мы имеем то же самое содержание (ту же информацию) –
объекты A, B, C, D, и разное представление-презентацию этой информации – рис.1 и рис.3.
Оказывается очень удобным не смешивать содержание (информацию) и представление (презентацию,
внешний вид). Это удобно по разным причинам. Обычно за саму информацию – содержание
– отвечает один человек, за ее
представление – другой. Внесение изменений и дополнений в содержание хотелось бы делать независимо от
представления, и наоборот, менять
внешний вид (представление, презентацию)
независимо от содержания.
Комментарий
Конечно, нельзя говорить о полной
независимости содержания и представления: если интернет страницу,
рекламирующую, например, детские игрушки, заполнить научной информацией, то
вряд ли получится хорошо. Обычно
фиксируется (в той или иной степени детализации) общие характеристики
содержания (информации), и под этот тип информации проектируется представление
(презентация). И независимость
представления и содержания существует в рамках этого типа содержания. Например,
один тип научного сайта может содержать краткие новости, более длинные рецензии
и статьи. Соответственно проектирование
представления-презентации такого сайта включает в себя разработку
представления (внешнего вида и расположения на интернет странице) для этих трех
типов объектов. Но если мы захотим
ввести на сайт, например, стенограммы заседания ученого совета, то потребуется
разработать представление для таких стенограмм
(введение нового типа информации-содержания требует разработки его представления).
Содержание страниц на рис.1 и 3 можно было бы записать в таком XML виде
(1) <AAA> описание объекта A</AAA>
<BBB> описание объекта B</BBB>
<CCC> описание объекта C</CCC>
<DDD> описание объекта D</DDD>
Конечно, тегам <AAA>, <BBB>, <CCC>, <DDD> нужно давать мнемонические названия, соответствующие
содержанию информации, которую эти теги
несут. Например, <новость_института> или <резюме_статьи>.
Заполнить такое описание тега может
человек, совсем не знакомый с языком
HTML, и даже не знающий, как эта информация будет расположена на странице
– он просто понимает название тегов и
заносит в них требуемую информацию.
Содержание объектов A, B, C, D может, конечно, не ограничиваться
только текстом, эти объекты могут в свою очередь содержать другие теги. Например,
тег <резюме_статьи> в свою очередь
может содержать теги <автор_статьи>,
<выходные_даннные_статьи> и др.
И для более сложных
объектов можно придумать XML язык описания, понятный неспециалисту. Человек,
отвечающий за содержание сайта, наполняет
такое описание конкретным содержанием (пишет содержание тегов).
Итак, роль XML – дать простое и понятное описание содержания страницы.
Остается презентация-представление этого содержания – эту страницу надо
показать в интернете в браузере пользователя.
Презентацию-представление содержания можно осуществлять
двумя способами. Первый способ – послать пользователю XML файл запрашиваемой страницы и
обеспечить, чтобы этот файл был проинтерпретирован браузером пользователя
должным образом. Однако такой подход
сдерживается отсутствием общепринятых стандартов (понимание XML языков всеми браузерами и пр.).
Второй способ – на стороне сервера анализируется запрашиваемый XML файл и строится обычная HTML страница, которая и посылается пользователю. В общих чертах опишем второй способ,
который и будет обсуждаться в этой
работе.
Нужно построить HTML страницу по ее XML описанию. Сначала рассмотрим, как
браузер пользователя интерпретирует HTML страницу. Браузер просматривает теги языка HTML
и определяет, как их надо
показывать на экране. Слова «как
показывать» означают: какое место на экране (относительно предыдущих
тегов) занимает содержимое рассматриваемого тега и как это содержимое должно выглядеть
(например, какой цвет и какой размер у текста, какой шрифт…). Если раньше (при
возникновении интерента) браузер пользователя получал лишь один HTML файл старницы, то по современной
технологии (которая успешно развивается примерно с 2000 года) браузер кроме
самой страницы получает еще и так называемую таблицу стилей этой страницы – в
эту таблицу обычно вынесены все инструкции о том, «как показывать» содержимое
тегов. Конечно, какие-то инструкции
можно оставлять и в HTML файле, но чем меньше инструкций оставляется,
тем лучше. Вначале HTML страницы обычно содержится ссылка
на один или несколько CSS файлов – на таблицы стилей этой страницы.
Информацию о том, «как показывать» теги браузер берет из CSS файла. На долю самой HTML
страницы остается информация обо всех объектах, которые должны
появится на странице – фактически это перечень всех объектов в нужной
последовательности, записанных на языке тегов HTML. Эти объекты имеют имена (class или id), которым соответствуют описания
(«как показывать») в таблице стилей CSS, см. следующий параграф,
посвященный CSS.
Итак, презентация-представление XML описания состоит из двух частей:
формирования перечня объектов страницы,
записанных в терминах тегов HTML, и построения таблицы стилей CSS для этих объектов.
Проиллюстрируем сказанное на примере XML описания (1). В первом приближении
оно трансформируется в такие HTML теги
(1’) <div class=”AAA”> описание объекта A</div>
<div class=” BBB”>описание объекта B</div>
<div class=”CCC”>описание объекта C</div>
<div class=”DDD”>описание объекта D</div>
Описания объектов A, B, C и D в свою очередь тоже преобразуются в
описания на языке HTML. За такие трансформации XML описания в HTML язык отвечает так называемое XSL преобразование. Вторая часть
настоящей работы целиком посвящена описанию технологии XSL преобразований.
Теперь для каждого объекта HTML страницы остается описать его стиль
в таблице стилей CSS. В данном случае в CSS определяются стили AAA, BBB, CCC и DDD (подробнее о CSS см. параграф 2).
Комментарий
Объекты HTML страницы могут формироваться
достаточно сложно: XSL преобразование может обращаться за
дополнительной информацией к внешним XML файлам (а не только к XML описанию самой страницы). Оно также
может делать различного рода вычисления при формировании HTML кода.
Итак XML-XSL технология распадается на три этапа. Первый – XML описание страницы, основное здесь –
достаточно простой, но емкий XML язык, на котором можно описать содержание страницы.
Второй этап – XSL преобразование, строящее HTML страницу по ее
XML описанию. Оно формирует объекты HTML страницы, дает им имена и пр. И
третий этап – все объекты приобретают нужный вид на странице с помощью
каскадных таблиц стилей CSS.
Отсюда становится примерно ясно, какие функции могут брать
на себя XML описание, XSL преобразование и таблицы стилей CSS.
Если мы хотим сделать изменения на странице, то в
зависимости от характера вносимых изменений
мы корректируем XML описание, XSL преобразование или таблицу стилей CSS. Например, увеличить левое поле
перед текстом или увеличить размер букв
можно, изменив CSS и не трогая XML описания и XSL преобразования.
Во многих случаях изменения можно вносить разными способами,
а мы можем выбирать из них самый удобный. Пусть, например, мы хотим на странице, изображенной на рис.1, поменять объекты A и D местами. Можно просто в XML описании страницы поменять местами
описания объектов A и D, см. (2), не трогая преобразования и таблицы стилей.
(2) <AAA> описание объекта D</AAA>
<BBB> описание объекта B</BBB>
<CCC> описание объекта C</CCC>
<DDD> описание объекта A</DDD>
Этого же можно добиться, не трогая XML описания и CSS, а изменив XSL преобразование (которое фактически
из (1) построит (2) и переведет в HTML вид). А можно, что наиболее корректно,
в XML описании
поменять теги <AAA> и <DDD> местами (конечно вместе с их содержимым) и в CSS переставить стили – стиль AAA станет стилем DDD и наоборот.
Еще один пример - мы
хотим из страницы на рис.1 сделать страницу на рис.3. Можно не менять XML описания, но изменить XSLT
преобразование и таблицу стилей CSS. Преобразование расставит объекты в
HTML файле в
нужном порядке, а CSS поменяет стили. Но можно
в XML описании изменить порядок перечисления объектов – тогда нам не
надо трогать XSL преобразования, а только изменить CSS.
2 Таблицы стилей CSS
Как говорилось выше, информация из таблицы стилей CSS используется браузером для определения
того, как объекты (теги) из HTML страницы должны выглядеть в браузере. То есть объектам (тегам)
соответствуют стили в таблице стилей CSS. Имя одной или нескольких таких
таблиц прописывается в начале HTML файла.
Теги с одинаковыми названиями (например <div>) могут находиться в разных местах HTML файла, нести разную функциональную
нагрузку и тем самым требовать разного представления (должны выглядеть по
разному).
Чтобы различать теги с тем же названием, тегам (объектам)
можно давать имена, т.е. снабжать теги
атрибутами двух видов – class и id. Значение id – уникальное, только один тег в HTML файле может иметь такое имя,
значение атрибута class может быть одинаково для нескольких тегов.
Конкретный стиль (одно описание в таблице стилей CSS)
может применяться ко всем экземплярам определенного тега, только к тегам
с определенными именами (уникальными или нет) и пр. В CSS
содержится описания стилей, а также информация, к каким тегам каждый стиль применяется. Эта
информация достаточно просто закодирована в самом названии стиля – что очень
удобно. Например, название стиля #name означает, что этот стиль
применяется к тегу с уникальным именем id=name.
Приведем примеры стилей. В стиле можно, например, указать,
что объект располагается слева и обтекается
справа – рис. 4.

Фрагмент кода HTML такой
<img
class=”picture” source=” foto.jpeg” width
= “90” height=”50”>
<div id=”comment1”>Здесь располагается текст
комментария</div>
Стиль картинки в таблице стилей CSS
.picture
{
float
left;}
Результат показан
на рис.4 – комментарий обтекает картинку
слева. Зададим еще и стиль комментария
.picture
{
float
left;}
#comment1:
{
margin-left:
100px;}
Тогда результат будет
такой, как на рис.5. Здесь margin-left: 100px;
означает отступ слева на 100 пикселей ( изображение имеет меньшую
ширину).
Как уже говорилось, браузер (программа, интерпретирующая HTML текст) последовательно просматривает текст страницы
и, найдя какой-то объект, располагает его в выходном потоке согласно его
стилю, описанному в таблице CSS. Положение объекта указывается относительно объемлющего его объекта (в
смысле HTML тегов) с учетом расположения
предыдущих объектов. Но в CSS есть возможность изменения
естественного порядка следования элементов – так называемое абсолютное
позиционирование (относительно окна броузера). Например
.picture{
position:absolute;
left:100px;
}
В таблице стилей CSS можно задавать много различных свойств объектов. Например – поля
относительно прямоугольника, в который объект вложен, рамки этого прямоугольник, фон прямоугольника (фон
объекта), различные свойства текста (шрифт, кегль и пр.).
Комментарий
С таблицами стилей работает и JAVA SCRIPT, т.е. стили объектов могут
быть изменены пользователем в процессе
просмотра интернет страницы (пользователь может даже подключать
разные CSS файлы – если это, конечно, предусмотрено в коде страницы).
Таблицы стилей CSS
поддерживаются всеми современными броузерами. Конечно, постоянно
разрабатываются новые версии CSS. Их поддержка неодинакова в разных
броузерах, но базовая часть CSS работает во всех браузерах очень
хорошо.
Тем не менее множество сайтов в интернете делается не по
этой технологии, а с использованием таблиц, о которых мы говорили в первом
параграфе. Игнорировать технологию CSS уже нельзя, но ее часто используют очень ограничено – в основном для
задания стилей текстов в ячейках таблицы. В чем же дело?
Как уже говорилось, до
появления CSS таблицы были единственным средством контролировать
расположение объектов на HTML странице. Первоначально тег «таблица» <table>
появился для изображения таблиц
данных. Теги <table>, <tr> (строка) и <td> (ячейка) позволяли определять число столбцов и строк в
таблице, размеры таблицы и ее ячеек, объединять ячейки таблицы в блоки и
вписывать в такие блоки не только числовые, но вообще любые данные. При возникновении интернета не очень
задумывались о представлении-презентации объектов на странице – главное,
чтобы они там появились и функционировали. Важно было, чтобы на странице можно
было сделать ссылку, разместить и отослать форму, чтобы была возможность просмотра
изображений и т.д.
Но в процессе развития интернета возникла потребность в том,
чтобы страница со всем своим
содержимым выглядела красиво. Захотелось управлять расположением
отдельных элементов на странице, но не
было предусмотрено никаких специальных
средств для этого. Оказалось, что
можно использовать для этих целей тег
таблицы <table>, хотя это
использование и довольно искусственное.
Страница рассматривается как большая таблица, она разбивается на ячейки, согласно дизайнерскому
замыслу эти ячейки объединяются в блоки и уже потом туда помещаются объекты страницы. Этот процесс на
очень простом примере описан в параграфе
1. Можно сказать, что использование
таблиц возникло не от хорошей жизни, а из-за абсолютного отсутствия надлежащих
средств форматирования.
Как подтверждение сказанному – в школе объяснить ученикам использование
таблиц для определения положения элементов на
странице (форматирования страницы) очень трудно. Что и естественно –
средство, придуманное для одних целей, используется совсем для других.
Использование таблиц для форматирования
(представления-презентации-дизайна) стало
уже довольно давней практикой, и естественно от нее трудно – прежде всего психологически – отказаться. Хотя уже довольно давно (примерно
с 2000 года) существует и хорошо себя зарекомендовало новое удобное средство –
таблицы стилей CSS.
Скажем несколько слов по поводу того, где стили могут
располагаться. Кроме отдельного файла CSS, адрес которого записывается в начале HTML файла (таких файлов может быть
несколько), стили могут быть записаны и непосредственно в HTML файле в теге <style
type="text/css" …> – это
«локальные» стили. Если в CSS есть
некоторые стили, то их можем переопределить «локальными» стилями, так как «локальные»
стили имеют приоритет. Возможно, локальные стили разумно помещать в XML описание страницы. «Локальные»
стили очень полезны – они позволяют менять стиль объекта только на одной
странице (на которой записан этот локальный стиль), оставляя стандартный стиль
(записанный в CSS) на всех других страницах.
Использование таблиц для дизайна
интернет-страниц очень похоже на использование
обычной «сетки» для дизайна полиграфической
продукции. Там пространство листа бумаги равномерно разбивается горизонтальными и вертикальными линиями.
Возникают ячейки, объединяя которые
дизайнер образует блоки, куда и вставляет элементы содержания. Сетки позволяют
унифицировать внешний вид многостраничной продукции – определенные элементы
содержания (например, колонтитулы) на каждой странице привязываются к тому же
блоку. Так что использование таблиц (фактически сеток) в web-программировании имеет под собой
веские основания. Есть, правда, существенная разница – лист бумаги имеет фиксированную
длину и ширину, а для интернет-страницы
эти параметры переменные, они зависят от
величины окна браузера.
Стиль WEB-программирования с
использованием CSS в принципе другой, чем стиль,
использующий таблицы. Создавая таблицу,
вы планируете, сколько колонок и строк в ней будет, затем вы объединяете нужные
ячейки для размещения там объектов страницы. То есть
различные объекты страницы оказываются как бы взаимосвязанными – и связывает их та таблица,
в которой они находятся. В CSS вы пишете стиль каждого объекта
отдельно, он идет в потоке объектов вашей HTML страницы и встает на свое место
согласно тому стилю, который ему задается в
таблице стилей CSS. Конечно, вы все равно следите за общим числом колонок
и за взаимным размещением разных объектов на странице, но делаете это другими средствами.
На расположение объектов внутри
таблицы влияют атрибуты таблицы cellspacing, cellpadding. Но кажется более разумным считать,
что расположение объекта относительно других
есть свойство самого этого
объекта. Так и делается в CSS.
На самом деле использование CSS
можно сочетать с использованием тега <table>. Вопрос просто в том, насколько
полно мы готовы использовать возможности
CSS.
Например, раньше было общей
практикой отступ текста делать введением пустой ячейки перед текстом и задавать ее
ширину. Это, конечно, в CSS
сделать гораздо проще (и экономнее).
По вопросу использования CSS есть много хороших источников – например,
www.w3c.org и www.zeldman.com .
3 XML описание содержания. Перевод в HTML
Ранее говорилось, что за представление-презентацию объектов HTML в браузере ответствечает таблица стилей CSS. Таблица стилей работает с
объектами (тегами) HTML страницы, сами эти объекты возникли
из содержания страницы. А как можно
удобным способом представить
содержание? В параграфе 1 мы
уже немного касались этого вопроса.
Разумно требовать, чтобы содержанием сайта мог заниматься человек, не знакомый с тонкостями
языка HTML. Писать такие теги, как <img id=”name” ….. /> или <div class=”classname”> (см. пример в начале параграфа
2) и в них вставлять содержимое – это не совсем правильно. Фактическое
содержание – например, название файла с изображением или текст подписи к
изображению – перемешано с мало
понятными постороннему человеку фрагментами языка HTML
<img id=”name” ….. >, <div class=”class”> и т.д. Если на странице
потребуется отобразить другую картинку и
к ней дать другой пояснительный текст, придется в HTML-коде найти нужные места и там произвести замену.
Это не очень сложная процедура, но мало
удобная. К тому же даже знакомый
с HTML пользователь может легко допустить ошибку – в сложном тексте ему надо вычленить
нужные фрагменты и заменить
их на другие.
Поэтому значительно лучше описывать страницу в тех терминах, которые удобны для
постороннего человека и для него понятны – понятны даже без особых специальных
комментариев.
На самом деле «посторонним человеком» может быть тот же
самый программист – ему тоже гораздо удобнее вносить изменения в XML файл, а не в файл HTML.
XML можно использовать для строгой записи любой информации.
Информация становится понятной без
дополнительных комментариев или с минимальными комментариями. Насколько понятна
- это
зависит от умения придумать такой XML язык. С другой стороны эта форма записи может быть
использована XSL преобразованиями для автоматического извлечения нужной
информации и ее дальнейшей обработки.
Поэтому мы будем стараться даже структуру папок новостного сайта
описывать в формате XML – и с минимальными
комментариями.
Содержание страницы, приведенной в
параграфе 2 на рис. 4, можно записать в XML виде, например, так
<picture>foto.jpeg
<foto_width> 200
</foto_width>
(3) <foto_height> 200
</foto_height>
</picture>
<comment>Это длинный текст к фотографии…
</comment>
Этот текст понятен без комментариев. Конечно,
предполагается, что читающий его человек
знает соглашения XML – описание между открывающим и закрывающим тегами относится
к понятию, которое тег обозначает. По традиции в названии тегов – эти
названия мнемоничны! – мы используем английские термины, хотя можно
было бы пользоваться и русскими.
Итак, преимущества такого XML языка перед HTML описанием
·
это
свободный язык, который мы сами придумываем для нашей задачи, а не стараемся
нашу задачу изложить на языке, уже заданном кем-то,
·
это
самодокументируемый язык – любой человек поймет, о чем здесь идет речь без
всякой документации (он только должен знать соглашения XML)
·
вам
не надо знать class, div и пр. деталей языка HTML. Наполнить XML-описание страницы новым содержанием
может посторонний человек
Но есть одно преимущество
HTML описания перед XML – HTML описание понимает любой браузер, в то же время XML
описание страницы ему не понятно.
Что нужно сделать, чтобы XML описание страницы показать в браузере?
Это мы делаем так, как упоминали в параграфе 1 – XML описание страницы с помощью программы на языке XSL
конвертируется в описание
страницы на языке HTML, которое уже понимает любой
браузер. Параллельно с такой программой
надо создавать таблицу стилей CSS, которая отвечает за представление HTML-тегов на странице.
В нашем примере фрагмент XML описания (3) должен превратиться в
такой фрагмент HTML
(4) <img id=”picture” source=”foto.jpeg” width = “200”
height=”200”/>
<div id=” comment ”>Это длинный текст к
фотографии…</div>
А дальше с помощью CSS браузеру надо указать, как эти HTML теги должны располагаться на странице
(см. примеры CSS к рис. 4 и 5)
Видно, что преобразование, переводящее описание (3) в
описание (4), очень простое – берутся
некоторые элементы XML описания и подставляются в HTML теги <img> и <div>. Если рассматривать преобразование
(3) в (4) как преобразование текстовых файлов, то его легко можно было бы
написать на любом языке программирования
Но мы будем использовать язык XSLT – этот язык был специально придуман для преобразования XML файлов в XML файлы (подробнее о специфике этого
языка см. вторую часть работы, параграф 6). Отметим, что мы пользуемся,
так сказать, «строгим вариантом» HTML языка XHTML, превращающим
HTML в XML-язык – например, обязательно
закрываются все открываемые теги, не
допускаются пустые атрибуты …
Итак, XSL преобразование трансформирует XML описание в HTML (даже в XHTML) описание страницы. Такое
преобразование в отличие от нашего примера выше может быть довольно сложным.
Например, XSL преобразование может
взять на себя некоторую «логику».
Пусть изображение может быть широким или узким. Тогда текст, поясняющий
изображение, может располагаться
по-разному в зависимости от ширины изображения, см.рис.6. Для широкого
изображения текст может быть внизу, а
для узкого – сбоку. XSL преобразование может
делать следующее: в случае, когда ширина изображения маленькая (проверяется
значение тега foto_width), теги <picture> и <comment> преобразуется в <img id=”small_picture” …> и <div class=” small_picture_comment” …..>, в противном случае – в теги <img id=”large_picture” …> <div class=”
large_picture_comment” ….>.
При этом мы ничего не
говорим о представлении-презентации, мы даем лишь разные имена тегам <img> и <div> в зависимости от ширины изображения.
А уже в таблице стилей CSS мы определим стили для пары small_picture,
small_picture_comment, а также для пары large_picture , large_picture_comment. Тем самым с помощью того же XSLT
преобразования и того же стилевого файла CSS можно получить различные
расположения изображения и его
комментария на странице (при
разных XML описаниях).
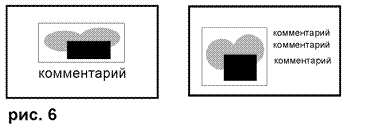
Во втором варианте расположения (картинка слева и текст рядом справа) мы можем с помощью
изменения CSS сделать наоборот – текст слева, картинка справа (вместо float:left; в CSS пишется float:right;)
Итак, описание интернет страницы можно делать на некотором простом XML языке, который специально для этого придумываем мы сами. Сложность
языка зависит от многообразия тех объектов, которые мы планируем размещать на
странице (и нашего умения). В этом языке используется лишь небольшая часть
всего арсенала средств, доступных в технологии XML. То же касается и XSLT
преобразований – используется лишь небольшая часть этого языка. Для
наших целей – XML описания интернет страниц и
трансляции этого описания в HTML код – этих ограниченных средств вполне достаточно.
На долю программиста ложится написание XSL преобразования, генерирующего HTML описание по XML описанию страницы, а также
написание таблицы стилей CSS.
Язык XSL преобразований нашел очень широкое применение, и не
только в WEB программировании, но и просто как язык для преобразования XML-структур данных.
Кроме использования в WEB программировании XML-XSL
технология используется для несколько других целей, связанных с работой
с большими объемами однородных данных (базами данных).
Информация
из базы данных легко записывается в формате
XML – можно, например,
ввести теги, соответствующие полям базы данных. И наоборот, если есть такой XML файл, из него
можно выбрать информацию и пополнить базу данных этой информацией. Поэтому
XML может играть роль универсального языка обмена
между различными базами данных. Точнее, данные из одной базы конвертируются в XML вид, потом
эти записи приводятся к другому XML виду, соответствующему записям во второй базе данных
(это делает XSL преобразование). А потом
эти данные заносятся во вторую базу. В настоящее
время любая база данных имеет
стандартные преобразователи записей – в XML формат и из XML формата. Проблема
преобразования данных между базами превращается в задачу написания соответствующего XSL
преобразования (если время преобразования не очень критично, см.
замечание 2 ниже)
Замечание 2
Представление
данных в
XML виде не очень
эффективно, оно явно избыточно – повторяются открывающие и закрывающие теги, и
большая часть документа может
идти на сопутствующую – обслуживающую
– информацию.
Но зато
представление в виде XML очень эффективно в другом смысле – оно очень простое как для понимания человеком, так и
для написания формальных преобразований.
В частности для написания анализаторов XML-языков (так называемых парсеров).
4 Сайты,
ориентированные на новости
Структура интернет сайтов может быть очень разнообразна, но
мы выделим только два типа сайтов. Первый тип – сайт для визуализации базы данных
Например, пусть есть база данных издательства. В некоторых
случаях вполне достаточно сделать одну
форму запроса к базе данных, и всю
нужную информацию получать из ответов на такие запросы.
Но возможно требуется некоторый сервис – целый набор страниц
сайта, которые, так сказать,
визуализируют эту базу. Например, страница – «Все авторы», выбирая автора мы
получаем все его книги. Или страница – «Тематика книг», выбирая тематику,
получаем все книги данной тематики. Может быть страница – изданные
книги по годам и т.д. По описанию самой
базы данных, ее полей и отношений
мы можем определить список
страниц этого сайта и связи между страницами.
Мы описываем понятия-сущности-entities, которые присутствуют в базе
данных, отсюда возникают разнообразные
блоки данных, из которых могут
компоноваться страницы. Некоторые связи между блоками данных можно установить
автоматически по описанию базы данных..
Такой подход – сайт на основе структуры базы данных – рассматривается в
проекте WebML, который довольно хорошо
представлен в интернете.
В базе данных обычно хранится однотипная информация –
например записи о книгах. Информация и
отношения между элементами информации регулярные – структура описания книги в
базе данных одинакова для всех книг, и для каждой книги присутствуют те же
связи (например название книги – автор – все книги этого автора и пр.).
Но часто мы встречаемся с нерегулярной информацией – это
второй тип сайта. Например, мы хотим делать
сайт организации. Нужно описать
структуру организации, чем она занимается, что-то сказать про сотрудников, о ее
истории, о ее достижениях за весь период существования – то есть нужно
собрать на сайте вообще-то довольно
разнородную информацию.
Структуру сайта, описывающего информацию из базы данных, можно представить
в виде графа, структура сайта с нерегулярной информацией больше похоже на дерево, чем на граф общего вида. Есть, например, главная страница сайта
организации, с нее есть ссылка на страницу истории, а с этой страницы - ссылка на страницу, посвященную основанию
организации. В таком дереве мы можем выйти на листья, которые могут вполне
соответствовать входу в подсайт,
связанный с базой данных. Например, такие страницы сайта, как
«структура организации»,
«сотрудники», « публикации сотрудников» - в принципе можно рассматривать как входы в
такие подсайты со своими базами
данных. Все зависит от того, насколько
подробно такие страницы нужно на сайте осветить. Например, страница сотрудников
может состоят только из какой-то общей
информации и возможности посмотреть curriculum vitae
отдельного сотрудника – этого может быть вполне достаточно. Но,
возможно, надо получать информацию о
всех публикациях сотрудника (из базы данных публикаций). Такого рода информация
содержится в различных файлах или базах данных, и в случае необходимости она может
появиться и на сайте организации – в той части сайта, которая занимается
визуализацией этой регулярной информации из баз данных.
Итак, по поводу структуры сайта организации ничего
регулярного сказать нельзя (по крайней мере
по поводу части такого сайта) – тем более для разных организаций
структуры их сайтов могут быть совершенно разными. В таких сайтах мы строим
последовательно страницу за страницей, начиная с главной – и
возникает дерево сайта. Конечно могут быть
и другие ссылки, превращающие дерево в граф, получается карта сайта. Но в
основе лежит все же дерево.
Язык XML удобен для
описания данных разной, не обязательно
регулярной, структуры. В частности на XML языке мы будем описывать содержимое
папок проектируемого сайта. Эти
папки содержат разнообразные файлы и описания этих папок в случае необходимости можно
обрабатывать XSL преобразованиями для получения
информации о дереве сайта.
Сайты организаций обычно содержат статичную, не меняющуюся или редко
меняющуюся, информацию и динамичную –
часто изменяемую информацию. Мы будем
рассматривать так называемые новостные сайты. Некоторые страницы таких
сайтов статичны, например страницы,
содержащие, структуру организации,
историческую информацию, другие страницы содержат новости – поток меняющейся информации.
В этой работе мы даем самое общее описание возможной
структуры таких новостных сайтов –
структуры, ориентированной на применение
XML-XSL технологии. Сначала несколько слов
об особенностях сайтов, которые мы собираемся описывать..
Мы предполагаем, что в таком сайте могут быть несколько
потоков новостей – разные каналы новостей, информация о которых пишется в один XML
файл news_list.xml. Тег <news> в этом файле
будет содержать конкретные новости, а его атрибут channel
определяет канал новости. Информация
о текущих публикациях будет находится в файле publications.xml,
который будет называться каналом публикаций. Он выделен в отдельный от news_list.xml файл из-за специфики работы с
публикациями (обычные новости более просты, чем публикации).
На каждой новостной странице появляются новости из некоторых (или всех) каналов новостей. В
описании страницы перечислены те каналы, новости из которых попадают на эту страницу.
На новостной странице кроме отображения новостей может быть еще некоторая информация
– условно мы ее называем информацией до новостей ( тег <pre>) и информацией после новостей
(тег <post>). Содержанием тега <pre> может быть, например, некоторая
общая информация о новостях, появляющихся на этой странице (например, тематика
новостей).
Страница начинается с заголовка. Там может быть логотип,
некоторое дополнительное изображение,
некоторая текстовая часть (название организации, название страницы). К
заголовку мы отнесем также и ссылки на так называемые сервисы страницы –
подписку на новости страницы (если страница новостная), ссылку на перевод
страницы, ссылку на RSS, а также поиск по сайту. Несколько подробнее о сервисах.
На новостных страницах есть ссылка, по которой можно
подписаться на те новости, которые появляются на этой странице –
подписчику по почте будет отправляться резюме этих новостей.
Заголовок любой страницы также содержит ссылку на страницу, посвященную RSS сайта. Технология RSS достаточно новая,
поэтому имеет смысл по этой ссылке уйти на отделную небольшую страницу,
на которой кратко описывать, что такое RSS (это краткое резюме сайта) и
привести несколько ссылок на сайты, на
которых понятие RSS обсуждается более детально. Естественно надо дать ссылку и на RSS-файл этого сайта.
Страницы сайта могут иметь (а могут не иметь) перевод на
иностранный (английский) язык – это отражается
в атрибуте translation основного тега
страницы <page>. Этот тег имеет атрибут –
это язык самой страницы. Страницы, для которых есть перевод, содержат ссылку на
переведенную страницу, ссылка будет находиться тоже в заголовке страницы. Подробнее об английской
версии страницы см. параграф 8.
Заголовки страницы (заголовку соответствует тег <header>) могут быть разными для разных
страниц сайта (например, заголовок первой страницы может содержать дополнительное изображение кроме
логотипа). Содержанием тега <header> может быть информация о том, из
каких изображений этот заголовок состоит, какие в нем надписи и пр. Или
информация, какой из нескольких типов заголовков появляется на этой странице, а описание самого заголовка может находится в
отдельном файле. В описании ниже атрибут type определяет тип заголовка.
Кстати о надписях в заголовке – они должны быть оформлены в
виде текста, а не быть частью изображения. Вообще, изображение из текста желательно делать только при крайней необходимости (например, в случае
логотипа) – текстовая информация всегда
должна быть доступна, даже в случае отключения картинок в браузере. А
картинки в интернете игнорируются довольно часто – можно самим отключить
изображения в броузере, изображения игнорируют программами чтения интернет
сайтов, которыми пользуются слепые люди, программы поиска по интернету тоже,
естественно, изображений анализировать не умеют.
Тег <navigation> отвечает за основное меню. Он
может содержать описание основного меню, или указывать XSL преобразованию на файл, который в
свою очередь описывает это меню. Удобно и
другие одинаковые элементы разных
страниц (например, заголовки страниц) описывать в отдельных файлах и на
каком-то этапе подсоединять их к странице. Описание элементов страницы в отдельных файлах может быть как XML описанием (например файл menu.xml, описывающий ссылки из основного
меню), так и XSL преобразованием. В последнем случае оно с помощью include подсоединяется к основному XSL преобразованию, строящему HTML страницы по их XML описаниям. Например, заголовок страницы описывается XSL преобразованием, XML описание заголовка нет смысла
делать – в заголовке все равно нельзя чисто механически изменить какие-нибудь элементы.
Заголовок делается индивидуально, расположение текста в заголовке зависит от
изображений, и, наоборот, величина
изображений зависит от текста в заголовке.
В конце параграфа 2 мы упоминали, что некоторые стили могут
быть записаны прямо в HTML файле страницы. Возможно, что такие стили
тоже разумно поместить в XML описание страницы – за это отвечает тег <local_css>. Этот тег может содержать все
«локальные» стили, а XSL преобразование эти стили просто вставляет в HTML код.
Каждая страница сайта сопровождается копирайтом и пр. За это
отвечает тег <footer>
Общая структура (схема) страницы сайта такова (детали,
конечно, могут меняться)
<page path="main/"
language="russian"
translation=”english” news_channels="main, publication">
<header type=”xx”/>
<navigation/>
<content>
Информация
зависит от типа страницы – новостная она или нет
</content>
<footer/>
<local_css>????
</local_css>
</page>
Все XML описания страниц преобразуются одним основным XSL преобразованием, которое находится
в базовой папке base (дерево всего сайта строится в базовой папке base). Значение атрибута path тега <page>
определяет положение
рассматриваемой страницы относительно базовой –пки. Атрибут language задает язык – то же самое
преобразование применяется для русских английских страниц сайта, см. парагоаф 8.
Атрибут translation определяет, есть ли перевод у этой страницы (если есть пара
атрибутов language="russian" translation=’english’, то на этой странице – русской странице
– есть ссылка на ее перевод на английский язык, аналогично для английской
страницы). Атрибут channels перечисляет каналы, на новости которых
подписана страница. Если атрибута нет, то страница не содержит новостей. Если
атрибут есть, то на странице есть подписка на новости этой страницы.
По тегу <header/> XSL преобразование вставляет «шапку» страницы, по тегу
<navigation/> - меню (для краткости можно говорить, что
вставляются значения тегов). Описание
меню хранится в отдельном файле menu.xml, который находится в базовой папке. О меню и его
английском варианте см. параграф 8.
Значение тега <footer>
(как, впрочем, и для <header>) может быть просто встроено в XSL преобразование, менять что-либо в
нем вообще не предполагается.
XSL преобразование, строящее страницы
сайта, выполняет несколько в принципе разных функций – строит заголовок
страницы, строит меню, анализирует содержимое тега <content>. Эти функции разумно
рассредоточить: построением значений тегов
<header> и <menu> занимаются отдельные XSL преобразования, а основное
преобразование занимается лишь анализом тега <content>. Все преобразования
объединяются вместе с помощью include. Схема XSL преобразования страницы приводится
в параграфе 9.
Если страница не новостная (т.е. атрибут channels отсутствует), то вся информация
страницы помещается непосредственно в
тег <content>. Эта информация будет описываться специальным XML языком. Если страница новостная, то
содержание тега <content>
записывается так
<pre>
Здесь помещается информация перед новостями
</pre>
<news/>
<post>
Здесь
помещается информация после новостей
</post>
Конечно, описание страницы может модифицироваться и детализироваться. Например, для информации в content, pre,
post должен быть придуман язык,
позволяющий отображать в этих элементах достаточно разнородную информацию – ту
информацию, которую предполагается туда помещать. Для такого описания в
настоящей работе мы ограничились тегом info_unit, в котором можно описать
изображение, текст и ссылку. Подробнее об этом теге и его расширении – в параграфе
7.
По тегу <news/> – если
он есть в описании страницы – нужно формировать
новости страницы. Тег news должен быть тогда, когда в описании страницы у тега
<page> есть атрибут channels (если страница не новостная, то
этого атрибута просто нет). Новости мы берем из файла news_list.xml – этот файл содержит
список всех новостей сайта в порядке поступления. Возможно, придется
обратиться еще и к файлу к файлу publication_list.xml, содержащему
информацию о новых публикациях. Аналогично новостям на сайте должны быть
представлены и события – это те же новости, но с датами. Фактически это анонсы
некоторых мероприятий.
Их отличие от новостей в том, что появляться на странице они должны не в
порядке поступления, а сортироваться по
дате. Конечно все это (и не только это)
должно найти свое место в языке описания содержания страницы.
Фактически теги <pre> и <post> определяют просто некоторые
блоки информации. Зачем надо их вводить, а не ограничится, например, одним
тегом <datablock>? Эти блоки имеют разное назначение, и в принципе они могут иметь разные
характеристики. Например, тег <post> на какой-то странице мы захотим
заполнить примечаниями, отделив примечания горизонтальной чертой от всей страницы. Тогда мы в локальных стилях
этой страницы – в начале этой HTML страницы – можем определить требуемый стиль для <post>, не затрагивая при этом <pre> (и совершенно не
затрагивая <pre> и <post> на других страницах).
Такое представление содержания ничем не ограничивает
возможности появления различной информации на странице. Все зависит от языка
описания содержания-контента.
5 Общая
структура новостного сайта
Здесь мы приблизительно опишем структуру папок
проектируемого новостного сайта.
Есть «базовая» папка base – папка, в которой содержится весь
сайт. В этой папке располагается общая информация, которая может потребоваться
для генерации отдельных страниц сайта.
Содержание этой папки описано в файле CONFIG.XML.
Примерное содержание папки base:
•
XML файл
CONFIG. Каждая
создаваемая папка содержит файл, описывающий содержание этой папки
• XML файл CONFIGSYS – файл содержит параметры всего сайта, например, максимальное
число новостей, отображаемой на любой новостной странице
• XSL-трансформации, с помощью которых из
XML описаний страниц
генерируются html страницы (таких преобразований несколько для разных частей страницы,
они объединяются через include в одном преобразовании index_transform),
• XML файл описания основного меню сайта
• XML файлы новостей и публикаций (news_list.xml и
publication_list.xml)
• Папка main -
папка основной страницы сайта
• Папка services – в ней содержатся файлы, связанные
с подпиской и RSS. На странице rss_about.xml
помещена краткая информация о том, что такое RSS и дается ссылка yна
собственное RSS сайта.
• Папка graphics – графика для заголовков страниц
• Папка enclosure – файлы, присоединяемые к новостям.
Присоединяемые файлы – файлы разных форматов, на которые могут ссылаться
новости.
Дерево всего сайта
строится следующим образом. Корень дерева – папка base. В папке base есть папка main –
в ней содержится основная
страница сайта (ее XML описание и пр.). Для каждой страницы основного меню в папке
base/main создается своя папка, где содержится XML описание этой страницы. Если на
такой странице есть ссылка на новую
внутреннюю страницу, то поступаем таким же образом – уже в папке этой
страницы создаем новую папку и помещаем
туда XML описание новой страницы. Таким образом, рекурсивно строится дерево
сайта, в каждой папке содержится одна внутренняя страница и быть может файлы (папки), эту страницу обслуживающие.
В так описанной процедуре генерации сайта могут быть,
конечно, исключения – некоторые
информационные страницы могут быть подчинены папке main, хотя и не входить в основное меню (хотя по значению в основное меню войти
бы могли, например информационная страница о сотрудниках).
Выше говорилось о так называемых «внутренних
страницах», т.е. о таких страницах, HTML код
которых строится по их XML описания. Но конечно на сайте есть
и «внешние» страницы – это такие страницы, которые сделал кто-нибудь другой не используя XML-XSL технологию. Они могут содержать
очень ценную информацию, это может быть и не страница, а целый сайт, таких
«внешних» страниц может быть довольно много.
Если есть ссылка на внешнюю страницу (то есть страницу, не
сделанную по этой XML-XSL технологии), то поступаем просто –
создаем новую папку и всю
информацию, связанную с это страницей помещаем в эту новую папку. Если была
ссылка на целый внешний сайт (совокупность
страниц), то создаваемая папка содержит весь этот сайт (то есть в папку копируется
вся структура этого сайта со всеми
файлами и подкаталогами)
Папки внутренних страниц могут содержать папку enclosure – для файлов, которые могут быть
приложены к описанию страницы (например, файлы изображений).
Каждая папка сайта содержит свой файл CONFIG, который описывает содержимое
папки. Вот, например, эскизный вариант
файла CONFIG.XML
в папке base, описанной в начале этого параграфа
<?xml version="1.0"
encoding="windows-1251"?>
<!-- * in base folder - all
files for reference **************-->
<config
path="…../base"> ***путь к папке base
<page_xml_files>***
xml файлы
<config.xml/>
<configsys.xml/>
<menu.xml/> menu items
<publication_list.xml/>
<news_list.xml/>
<event_list.xml/>
</page_xml_files>
<index_transform>
***преобразования, из которых
собирается index_transform.xsl
<hearder.xsl/> ***преобразование
для заголовка
<menu.xsl/> ***преобразование
для меню
<configsys.xsl/> ***параметры
из файла configsys.xml
<content_language.xsl/> ***шаблоны
<news_language.xsl/> ***шаблоны
.........
</index_transform>
<folders> ***папки,
содержащиеся в base
<main/> ***основная страница сайта
<graphic_files/> ***графика
<encloser_files/> ***присоединяемые
к новостям файлы
<services/>
</folders>
<css_fifes>
<ipm.css/> ***общая
таблица стилей
</css_fifes>
<dtd_files>
***????***
</dtd_files>
</config>
Файлы CONFIG.XML
пишутся более или менее произвольно, они являются рабочим инструментом с
комментариями. Но в принципе их можно
использовать в XML-XSL технологии, например, для получения информации о дереве
сайта.