|
Часть
1 |
|
дата документа: февраль. 2000 |
- дата последнего обновления19.10.10 - |
DVM отладчик предназначен для отладки DVM-программ (написанных на языках Fortran-DVM и C-DVM). Для отладки DVM-программ используется следующий подход. Сначала программа отлаживается на рабочей станции как последовательная программа с использованием обычных средств отладки. Затем программа выполняется на той же рабочей станции в специальном режиме проверки DVM-директив. На третьем этапе программа выполняется на параллельном компьютере в специальном режиме сравнения промежуточных результатов выполнения с эталонными результатами (например, с результатами последовательного выполнения).
DVM-программа может содержать ошибки разного рода. DVM-отладчик предназначен для поиска тех ошибок, которые не проявляются при последовательном выполнении DVM-программы.
В общем случае можно выделить следующие четыре класса ошибок:
Синтаксические ошибки в DVM-указаниях (неправильная запись оператора, отсутствие скобки и т.д.), а также нарушение статической семантики.
Неправильная последовательность выполнения DVM-указаний или неправильные параметры DVM-указаний.
Неправильное выполнение вычислений из-за некорректности DVM-указаний и ошибок, не проявляющихся при последовательном выполнении программы.
Аварийное завершение параллельного выполнения программы (авосты, зацикливания, зависания) из-за ошибок, не проявляющихся при последовательном выполнении программы.
Ошибки первого класса выявляются при компиляции.
С ошибками второго класса справиться посредством статического анализа программ невозможно (за исключением простейших случаев, например, задание неверного типа параметра). Чтобы обнаруживать ошибки этого класса каждая функция библиотеки Lib-DVM проверяет корректность порядка выполнения DVM-указаний и передаваемых параметров. Данные проверки осуществляется динамически во время параллельного выполнения программы. Некоторые из таких проверок могут вызывать заметные накладные расходы и поэтому производятся только по специальному указанию.
Обнаружение ошибок третьего класса невозможно при параллельном выполнении без специального режима компиляции и значительных накладных расходов. Примером такой ошибки может служить указание о параллельном выполнении цикла, между витками которого имеется зависимость по данным, которую программист не специфицировал. Для ее обнаружения необходимо фиксировать все операции модификации и использования данных, осуществляемые на разных процессорах, и выявлять случаи использования на одном процессоре переменных, модифицируемых другим процессором. Такого рода контроль может быть выполнен эффективнее в случае выполнения программы на одном процессоре в режиме имитации параллельного выполнения.
DVM отладчик предназначен для обнаружения ошибок третьего класса и базируется на следующих двух методах.
Первый метод, метод динамического контроля DVM-указаний, позволяет проверить корректность распараллеливания программы с помощью DVM-указаний. Он основан на анализе последовательности вызовов функций Lib-DVM и обращений к переменным во время моделирования на одном процессоре параллельного выполнения программы.
Второй метод основан на сравнении результатов выполнения программы в последовательном и параллельном режиме. Он позволяет определить место в программе и момент, когда появятся расхождения в результатах вычислений, которые могут быть вызваны либо неверной спецификацией параллелизма с помощью DVM-указаний, либо ошибкой последовательного алгоритма, проявляющейся только при его параллельном выполнении. При этом, в отличие от первого метода, только часть программы может быть скомпилирована в специальном режиме.
Входящие в состав отладчика средства накопления результатов параллельного выполнения программы могут оказаться полезными и для обнаружения ошибок четвертого класса. Кроме того, для обнаружения таких ошибок предназначен механизм накопления системной трассировки (трассировки вызовов функций системы поддержки выполнения DVM-программ).
1.1 Метод динамического контроля DVM-указаний
Динамический контроль основан на моделировании параллельного выполнения DVM-программы на одном процессоре. Использование данного метода может существенно замедлить выполнение программы и требует больших объемов дополнительной памяти. Поэтому, он может применяться только для программы со специально подобранными тестовыми данными ограниченного объема.
Средства динамического контроля позволяют выявлять следующие типы ошибок:
Необъявленная зависимость по данным в параллельном цикле или между параллельными задачами.
Чтение неинициализированных переменных.
Модификация в параллельной конструкции нераспределенных переменных, которые не являются редукционными или приватными.
Использование редукционных переменных после запуска асинхронной редукции, но до ее завершения.
Выход за пределы распределенного массива.
Необъявленный доступ к нелокальным элементам распределенного массива.
Запись в теневые грани распределенного массива.
Чтение теневых элементов массива до завершения операции их обновления.
1.3 Метод сравнения результатов выполнения
Динамический контроль предназначен, прежде всего, для проверки корректности DVM-указаний. Область контроля ограничена только DVM-программами, скомпилированными в специальном отладочном режиме. Однако, в программе возможны обращения к процедурам, написанным на обычных последовательных языках (включая ассемблер). Работа таких процедур, которая не контролируется, может быть причиной некорректного параллельного выполнения программы. И, наконец, в программе могут быть ошибки (не связанные с ее распараллеливанием), которые не проявлялись при ее последовательном выполнении, но приводят к неверному параллельному выполнению.
Для поиска таких ошибок предназначен другой метод контроля. Этот метод основывается на накоплении результатов вычислений при разных условиях выполнения и сравнении полученных результатов. При использовании этого метода программа может выполняться в двух режимах. В одном режиме результаты вычислений (значения переменных) накапливаются и записываются в файл как эталонные. В другом режиме результаты вычислений сравниваются с эталонными. При этом учитывается, что значения некоторых переменных (например, редукционных внутри параллельных конструкций) могут различаться.
Отладчик можно разбить на две, четко выраженные, системы: динамический контроль и сравнение результатов выполнения.
Обе эти системы используют следующие базовые подсистемы: таблицы, позволяющие хранить однотипную информацию большого объема, хэш-таблицы для организации быстрого поиска данных по ключу и модуль выдачи диагностики.
На базе этих двух подсистем строятся остальные системы, более высокого уровня.
Динамический контроль включает в себя следующие компоненты:
Таблица переменных. Предоставляет методы для накопления информации об использовании разнотипных переменных в системе, а также быстрой выборки этой информации по адресу переменной.
Модуль динамического контроля. Осуществляет непосредственную проверку DVM-указаний. Обращение к этому модулю идет из некоторых функций библиотеки Lib-DVM, а так же при каждом обращении к переменной или массиву. Таблица переменных используется как вспомогательный модуль, в котором накапливается или извлекается информация о переменных в ходе динамического контроля.
Система сравнения результатов вычислений включает в себя следующие компоненты:
Блок накопления трассировки в памяти. Производит накопление и структуризацию трассировочных событий в ходе выполнения программы.
Блок записи трассировки в файл. Используется из блока накопления трассировки при задании режима записи трассировки в ходе выполнения программы.
Блок чтения трассировки из файлов. Использует как вспомогательный блок накопления трассировки.
Блок сравнения трассировок. Сравнивает события трассируемой программы с эталонной трассировкой, сформированной предварительно в памяти блоком накопления трассировки.
Блок контроля редукционных переменных. Осуществляет эмуляцию выполнения каждого витка цикла и каждой параллельной задачи на своем процессоре для ручного просчета операции редукции. Работает только при задании соответствующего режима.
3 Прототипы отладочных функций
Система поддержки Lib-DVM содержит дополнительные системные вызовы, относящиеся к динамическому отладчику и отвечающие за динамический контроль и сравнение трассировки. Обращения к данным вызовам подставляются компиляторам C-DVM и Fortran-DVM при компиляции программы в специальном отладочном режиме.
Прототипы отладочных функций следующие:
|
long dprstv_ (long *TypePtr, AddrType *addr,
long *Handle, char *Operand, |
||
|
|
|
|
|
TypePtr |
– |
тип переменной (константы rt_INT, rt_LONG, rt_FLOAT или rt_DOUBLE). Если тип не соответствует ни одному из стандартных типов, то данное обращение будет проигнорировано для трассировки; |
|
addr |
– |
адрес переменной или элемента массива; |
|
Handle |
– |
дескриптор DVM-массива, если обращение идет к элементу массива. Иначе аргумент должен быть равным NULL; |
|
Operand |
– |
строка с именем операнда. Данная строка будет выводиться в сообщениях об ошибках и трассировке; |
|
OperLength |
– |
длина строки, переданной в Operand. Данный аргумент служит для совместимости с Fortran. При вызове из Си должен быть равен –1. |
Функция отмечает начало модификации переменной или элемента массива. Вызов должен вставляться до присвоения переменной значения и до вычисления присваиваемого выражения. Данный системный вызов должен быть парным с dstv_().
|
long dstv_(void) |
Функция отмечает завершение вычисления выражения и присвоение переменной нового значения. Функция должна вызываться после присвоения переменной нового значения и должна быть парной с вызовом dprstv_().
|
long dldv_(long *TypePtr, AddrType *addr, long
*Handle, char *Operand, |
||
|
|
|
|
|
TypePtr |
– |
тип переменной (константы rt_INT, rt_LONG, rt_FLOAT или rt_DOUBLE). Если тип не соответствует ни одному из стандартных типов, то данное обращение будет проигнорировано для трассировки; |
|
addr |
– |
адрес переменной или элемента массива; |
|
Handle |
– |
дескриптор DVM-массива, если обращение идет к элементу массива. Иначе аргумент должен быть равным NULL; |
|
Operand |
– |
строка с именем операнда. Данная строка будет выводиться в сообщениях об ошибках и трассировке; |
|
OperLength |
– |
длина строки, переданной в Operand. Данный аргумент служит для совместимости с Fortran. При вызове из Си должен быть равен –1. |
Функция отмечает обращение к переменной или элементу массива на чтение.
|
long dbegpl_(long *Rank, long *No, long *Init, long *Last, long *Step) |
||
|
|
|
|
|
Rank |
– |
ранг параллельного цикла; |
|
No |
– |
номер конструкции. Должен быть уникален для всех циклов и областей задач в пределах одной программы; |
|
Init |
– |
массив размерности Rank начальных значений итерационных переменных цикла; |
|
Last |
– |
массив размерности Rank конечных значений итерационных переменных цикла; |
|
Step |
– |
массив размерности Rank значений шага итерационных переменных. |
Функция отмечает начало параллельного цикла. Обращение к данному вызову должно идти до отображения параллельного цикла ( функция mappl).
|
long dbegsl_(long *No) |
||
|
|
|
|
|
No |
– |
номер конструкции. Должен быть уникален для всех циклов и областей задач в пределах одной программы. |
Функция отмечает начало последовательного цикла. Ранг последовательного цикла всегда принимается равным 1.
|
long dbegtr_(long *No) |
||
|
|
|
|
|
No |
– |
номер конструкции. Должен быть уникален для всех циклов и областей задач в пределах одной программы. |
Функция отмечает начало области задач. Ранг области задач всегда принимается равным 1.
|
long dendl_(long *No, unsigned long *Line) |
||
|
|
|
|
|
No |
– |
номер завершающейся конструкции; |
|
Line |
– |
строка, в которой произошел выход из конструкции. Служит для контроля корректности завершения параллельных циклов. |
Функция отмечает завершение последовательного или параллельного цикла или области задач. Должна вызываться после завершения последней итерации цикла или последней задачи из области задач.
|
long diter_(AddrType *index) |
||
|
|
|
|
|
index |
– |
массив адресов итерационных переменных. Размерность массива должна совпадать с рангом исполняющейся конструкции. |
Функция отмечает начало новой итерации последовательного или параллельного цикла или начало новой параллельной задачи. При использовании в многомерных параллельных циклах, обращение к функции должно идти после модификации всех итерационных переменных цикла. Для области задач в качестве аргумента функции должна передаваться переменная, содержащая номер текущей исполняющейся параллельной задачи.
|
long drmbuf_(long* ArrSrc, AddrType* RmtBuff, long* Rank, long* Index) |
||
|
|
|
|
|
ArrSrc |
– |
дескриптор исходного DVM-массива, для которого создается буфер удаленного доступа; |
|
RmtBuff |
– |
адрес скалярной переменной, если буфер создается для единичного элемента массива, или дескриптор DVM-массива, выполняющего роль буфера, если буфер создается для вырезки массива; |
|
Rank |
– |
ранг буфера удаленного доступа. Должен быть равен 0, если буфер создается в скалярной переменной; |
|
Index |
– |
массив, содержащий индексы вырезаемых измерений. Если элемент массива не равен -1, то из DVM-массива берется вырезка, соответствующая данному элементу массива, иначе берется все измерение массива. |
Функция регистрирует в системе динамического контроля создание буфера удаленного доступа. Данная функция необходима для корректного контроля обращений к элементам DVM-массива через буфер удаленного доступа. Вызов должен стоять после создания буфера и инициализации его элементов.
|
long dskpbl_(void) |
Функция отмечает завершения блока собственных вычислений в последовательной ветви программы. Обращение к функции должно стоять после выполнения соответствующей группы операторов.
Таблица предназначена для хранения данных большого объема. Особенностью ее реализации является то, что память под данные выделяется не под каждый элемент, а сразу для нескольких элементов. Число элементов, под которое выделяется память, определяется параметрически, при инициализации таблицы. Таблица расширяется автоматически, при заполнении текущего выделенного объема памяти.
Для таблицы определена структура данных следующего вида:
|
typedef struct tag_TABLE |
||||
|
{ |
|
|
||
|
|
byte |
IsInit; |
||
|
|
s_COLLECTION |
cTable; |
||
|
|
size_t |
TableSize; |
||
|
|
size_t |
CurSize; |
||
|
|
size_t |
ElemSize; |
||
|
|
PFN_TABLE_ELEMDESTRUCTOR |
Destruct; |
||
|
} |
TABLE; |
|
||
|
|
|
|
||
|
IsInit |
– |
флаг инициализации таблицы. Используется для отложенной инициализации в целях оптимизации работы; |
||
|
cTable |
– |
коллекция указателей на выделенные фрагменты памяти; |
||
|
TableSize |
– |
число элементов, для которого будет выделена память при расширении таблицы; |
||
|
CurSize |
– |
число занятых элементов в текущем выделенном фрагменте памяти; |
||
|
ElemSize |
– |
размер в байтах одного элемента; |
||
|
Destruct |
– |
указатель на функцию с
прототипом |
||
Прототипы функций для работы с таблицей:
|
void table_Init(TABLE *tb, size_t TableSize, size_t ElemSize, PFN_TABLE_ELEMDESTRUCTOR Destruct) |
||
|
|
|
|
|
tb |
– |
указатель на инициализируемую таблицу; |
|
TableSize |
– |
число элементов, под которое будет выделена память при расширении таблицы; |
|
ElemSize |
– |
размер элемента таблицы; |
|
Destuct |
– |
указатель на функцию-деструктор элемента таблицы. Может быть равен NULL. |
Функция инициализации таблицы. Данная функция должна быть вызвана перед началом работы с таблицей.
|
void table_Done( TABLE *tb ) |
||
|
|
|
|
|
tb |
– |
указатель на таблицу. |
Деструктор таблицы. Должен быть вызван после завершения работы с таблицей для освобождения используемой памяти. Вызывает деструктор элемента для каждого элемента таблицы.
|
long table_Count( TABLE *tb ) |
||
|
|
|
|
|
tb |
– |
указатель на таблицу. |
Функция возвращает число помещенных элементов в таблице.
|
void *table_At( TABLE *tb, long No ) |
||
|
|
|
|
|
tb |
– |
указатель на таблицу; |
|
No |
– |
номер элемента. Нумерация элементов в таблице идет с 0. Если No выходит за пределы числа элементов, то программа аварийно завершается. |
Функция возвращает указатель на элемент таблицы с номером No.
|
long table_Put( TABLE *tb, void *Struct ) |
||
|
|
|
|
|
tb |
– |
указатель на таблицу; |
|
Struct |
– |
указатель на вставляемый элемент. В таблицу будет помещено только ElemSize байт указанной структуры. |
Функция добавляет новый элемент в конец таблицы.
|
void *table_GetNew( TABLE *tb ) |
||
|
|
|
|
|
tb |
– |
указатель на таблицу. |
Функция выделяет место для нового элемента в таблице и возвращает указатель на выделенную память. Использование данной функции более оптимально, чем table_Put(), так не выполняет дополнительного копирования блока памяти.
|
void table_RemoveFrom( TABLE *tb, long Index ) |
||
|
|
|
|
|
tb |
– |
указатель на таблицу; |
|
Index |
– |
номер элемента, после которого будет произведено удаление. |
Функция удаляет из таблицы элементы, начиная с номера Index+1. Сам элемент с номером Index из таблицы не удаляется.
|
void table_RemoveAll( TABLE *tb ) |
||
|
|
|
|
|
tb |
– |
указатель на таблицу. |
Функция удаляет все элементы из таблицы. Функция освобождает всю память, выделенную для хранения элементов таблицы.
|
void table_Iterator(TABLE *tb, PFN_TABLEITERATION
Proc, |
||
|
|
|
|
|
tb |
– |
указатель на таблицу; |
|
Proc |
– |
итерационная функция с
прототипом |
|
Param1 |
– |
параметр, передаваемый как Param1 в функцию Proc; |
|
Param2 |
– |
параметр, передаваемый как Param2 в функцию Proc. |
Функция выполняет однотипную операцию для всех элементов таблицы.
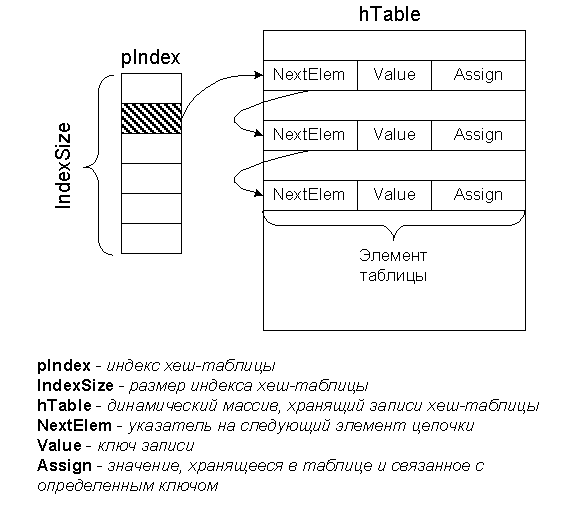
Хеш-таблица предназначена для быстрого поиска записей по их ключу. Она организована в виде индекса фиксированной длины и цепочек записей, связанных с каждым элементом индекса. Каждая запись содержит помещаемое в хеш-таблицу значение, его ключ и ссылку на следующую запись цепочки.
При помещении новой записи в хеш-таблицу, для ее ключа вычисляется хеш-значение, которое находится в фиксированном диапазоне [0, IndexSize]. Это значение является номером элемента в индексе хеш-таблицы, куда помещается указатель на новую запись цепочки. Предыдущий указатель сохраняется во вставляемой записи.
Поиск в хеш-таблице осуществляется по следующему алгоритму. По ключу искомой записи вычисляется хеш-значение. По этому значению из индекса хеш-таблицы извлекается указатель на первую запись цепочки. Далее в цикле пробегаются все записи этой цепочки и сравниваются с искомой записью по значению ключа. При нахождении совпадения, найденная запись возвращается как результат поиска.
Для вычисления хеш-значений используются следующие два алгоритма:
StandartHashCalc. Вычисление производится по формуле HASH = (long)Key % HashIndexSize, где Key – ключ записи, HashIndexSize – размер индекса хеш-таблицы и % – обозначает операцию вычисления остатка от деления.
OffsetHashCalc. Вычисление производится по формуле HASH = ((long)Key >> Offset) % HashIndexSize, где Key – ключ записи, HashIndexSize - размер индекса хеш-таблицы, Offset - задаваемое параметрически смещение, % - обозначает операцию вычисления остатка от деления и >> обозначает операцию побитового сдвига влево. При Offset = 0, алгоритм совпадает с StandartHashCalc.
Следующий рисунок показывает схематическую реализацию хеш-таблицы.
Рис. 1. Организация хеш-таблицы
Для работы с хеш-таблицей описаны следующие типы и структуры:
Хеш-значение:
|
typedef size_t HASH_VALUE |
Тип данных, служащий для ассоциативного поиска. По данному типу вычисляется хеш-значение:
|
typedef unsigned long STORE_VALUE |
Структура для хранения элемента хеш-таблицы:
|
typedef struct tag_HashList |
|
{ |
|
|
||
|
|
long |
NextElem; |
||
|
|
STORE_VALUE |
Value; |
||
|
|
long |
Assign; |
||
|
} |
HashList; |
|
||
|
|
|
|
||
|
NextElem |
– |
номер следующего элемента цепочки. Если равен 0, то это последний элемент цепочки |
||
|
Value |
– |
ключ, с которым ассоциируется хранимое значение |
||
|
Assign |
– |
хранимое значение |
||
Структура, описывающая хеш-таблицу:
|
typedef struct tag_HASH_TABLE |
|
{ |
|
|
||
|
|
TABLE |
hTable; |
||
|
|
long * |
pIndex; |
||
|
|
size_t |
IndexSize; |
||
|
|
PFN_CALC_HASH_FUNC |
HashFunc; |
||
|
|
unsigned long * |
pElements; |
||
|
|
unsigned long |
statCompare, statPut, statFind; |
||
|
} |
HASH_TABLE; |
|
||
|
|
|
|
||
|
hTable |
– |
таблица для хранения элементов хеш-таблицы; |
||
|
pIndex |
– |
массив для указателей на начало цепочек. Хеш-значение определяет номер элемента в этом массиве; |
||
|
IndexSize |
– |
размер массива pIndex; |
||
|
HashFunc |
– |
указатель на функцию для вычисления хеш-значения по ключу; |
||
|
pElements |
– |
массив, каждый элемент которого хранит длину цепочки по соответствующему элементу в pIndex. Служит для хранения статистики плотности заполнения хеш-таблицы; |
||
|
statCompare, statPut, statFind |
– |
данные поля содержат число операций сравнения, вставки и поиска, произведенных с хеш-таблицей. |
||
Прототипы функций для работы с хеш-таблицей:
|
void hash_Init(HASH_TABLE *HT, size_t IndexSize, int TableSize, PFN_CALC_HASH_FUNC Func) |
||
|
|
|
|
|
HT |
– |
указатель на хеш-таблицу; |
|
IndexSize |
– |
размер массива индексов; |
|
TableSize |
– |
величина приращения для таблицы элементов; |
|
Func |
– |
функция вычисления хеш-значения. Если параметр равен NULL, то будет применяться стандартная функция StandartHashCalc, работающая по формуле: <хеш-значение> = <ключ> % IndexSize. |
Функция инициализирует хеш-таблицу. Производит инициализацию и заполнение всех необходимых структур.
|
void hash_Done( HASH_TABLE *HT ) |
||
|
|
|
|
|
HT |
– |
указатель на хеш-таблицу. |
Деструктор хеш-таблицы. Освобождает всю память, выделенную под хеш-таблицу.
|
long hash_Find( HASH_TABLE *HT, STORE_VALUE Val ) |
||
|
|
|
|
|
HT |
– |
указатель на хеш-таблицу; |
|
Val |
– |
ключ, по которому осуществляется поиск. |
Функция осуществляет поиск значения по ключу.
|
void hash_Insert( HASH_TABLE *HT, STORE_VALUE Val, long Assign ) |
||
|
|
|
|
|
HT |
– |
указатель на хеш-таблицу; |
|
Val |
– |
ключ вставляемого элемента; |
|
Assign |
– |
число, ассоциированное с данным ключом. |
Функция вставляет новый элемент в хеш-таблицу.
|
void hash_Change( HASH_TABLE *HT, STORE_VALUE Val, long Assign ) |
||
|
|
|
|
|
HT |
– |
указатель на хеш-таблицу; |
|
Val |
– |
ключ изменяемого элемента; |
|
Assign |
– |
новое число, ассоциированное с данным ключом. |
Функция изменяет ассоциированного значения для заданного ключа.
|
void hash_Remove( HASH_TABLE *HT, STORE_VALUE Val ) |
||
|
|
|
|
|
HT |
– |
указатель на хеш-таблицу |
|
Val |
– |
ключ удаляемого элемента |
Функция удаляет элемента из хеш-таблицы по заданному ключу.
|
void hash_Iterator(HASH_TABLE *HT, PFN_HASHITERATION
Proc, |
||
|
|
|
|
|
HT |
– |
указатель на хеш-таблицу; |
|
Proc |
– |
итерационная функция с
прототипом: |
|
Param |
– |
Дополнительный параметр, передаваемый в функцию Proc. |
Функция выполняет однотипную операцию над всеми элементам хеш-таблицы.
|
void hash_RemoveAll( HASH_TABLE *HT ) |
||
|
|
|
|
|
HT |
– |
указатель на хеш-таблицу. |
Функция удаляет все элементы хеш-таблицы.
Таблица переменных предназначена для хранения записей, описывающих переменные, и поиска этих записей с использованием хеш-таблицы.
Каждая запись таблицы содержит следующую информацию о переменной: адрес, уровень исполнения программы, в котором эта запись была создана, класс использования переменной и дополнительная информация, определяемая классом использования.
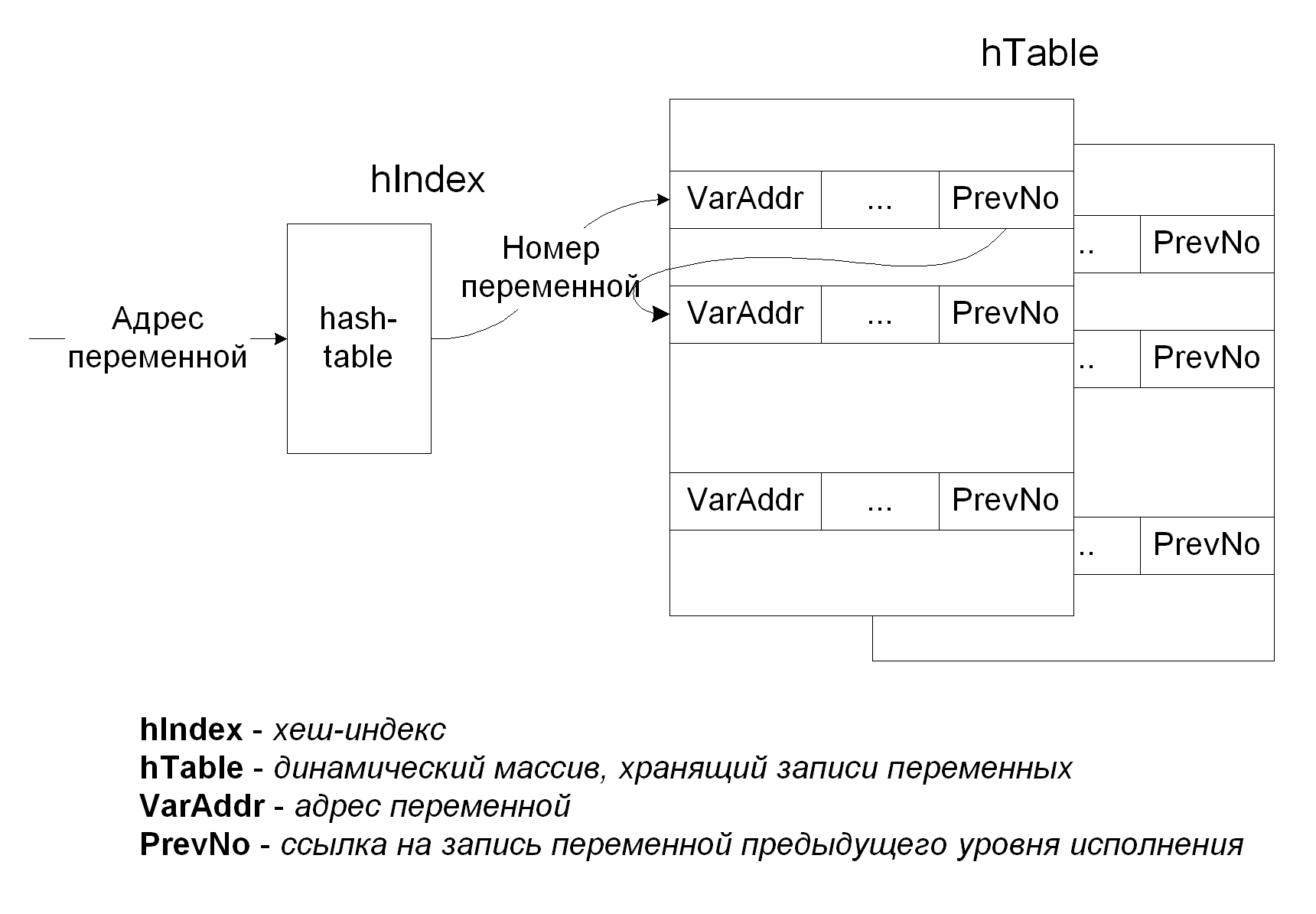
Рис. 2. Структура таблицы
переменных
Для хранения информации о переменной используется следующая структура:
|
typedef struct tag_VarInfo |
||||
|
{ |
|
|
||
|
|
byte |
Busy; |
||
|
|
void * |
VarAddr; |
||
|
|
long |
PrevNo; |
||
|
|
int |
EnvirIndex; |
||
|
|
byte |
Type; |
||
|
|
SysHandle * |
Handle; |
||
|
|
void * |
Info; |
||
|
|
int |
Tag; |
||
|
|
byte |
IsInit; |
||
|
|
PFN_VARTABLE_ELEMDESTRUCTOR |
pfnDestructor; |
||
|
} |
VarInfo; |
|
||
|
|
|
|
||
|
Busy |
– |
флаг, указывающий свободна эта структура или нет. Служит для оптимизации операций с таблицей переменных; |
||
|
VarAddr |
– |
адрес переменной; |
||
|
PrevNo |
– |
номер элемента таблицы переменных, описывающий ту же переменную в другом контексте выполнения; |
||
|
EnvirIndex |
– |
номер уровня исполнения программы для данной переменной; |
||
|
Type |
– |
класс переменной; |
||
|
Handle |
– |
указатель на дескриптор распределенного массива. Не равен NULL, если структура описывает распределенный массив; |
||
|
Info |
– |
указатель на дополнительное описание переменной; |
||
|
Tag |
– |
флаг для хранения различных атрибутов переменной в зависимости от класса ее использования; |
||
|
IsInit |
– |
флаг инициализации переменной. Используется для скалярных переменных; |
||
|
pfnDestructor |
– |
указатель на деструктор описания переменной. Данная функция будет вызвана при удалении описания переменной из таблицы переменных. Может быть равен NULL. |
||
Следующая структура описывает таблицу переменных:
|
typedef struct tag_VAR_TABLE |
||||
|
{ |
|
|
||
|
|
HASH_TABLE |
hIndex; |
||
|
|
TABLE |
vTable; |
||
|
} |
VAR_TABLE; |
|
||
|
|
|
|
||
|
hIndex |
– |
хеш-таблица для поиска информации о переменной по ее адресу; |
||
|
vTable |
– |
таблица для хранения описаний переменных. |
||
Прототипы функций для работы с таблицей переменных:
|
void vartable_Init( VAR_TABLE *VT, int vTableSize, int
hIndexSize, int
hTableSize, |
||
|
|
|
|
|
VT |
– |
указатель на таблицу переменных; |
|
vTableSize |
– |
размер приращения таблицы vTable; |
|
hIndexSize |
– |
размер массива индексов хеш-таблицы hIndex; |
|
hTableSize |
– |
размер приращения хеш-таблицы hIndex; |
|
Func |
– |
указатель на функцию, используемую для вычисления хеш-значения по адресу переменной. |
Функция инициализирует таблицу переменных.
|
void vartable_Done( VAR_TABLE *VT ); |
||
|
|
|
|
|
VT |
– |
указатель на таблицу переменных |
Деструктор таблицы переменных.
|
VarInfo *vartable_GetVarInfo( VAR_TABLE *VT, long NoVar ) |
||
|
|
|
|
|
VT |
– |
указатель на таблицу переменных; |
|
NoVar |
– |
номер переменной в таблице. |
Функция осуществляет поиск информации о переменной по ее номеру. Возвращает указатель на структуру с описанием переменной.
|
VarInfo *vartable_FindVar( VAR_TABLE *VT, void * Addr ) |
||
|
|
|
|
|
VT |
– |
указатель на таблицу переменных; |
|
Addr |
– |
адрес переменной. |
Функция осуществляет поиск информации о переменной по ее адресу. Возвращает указатель на структуру с описанием переменной или NULL, если переменная с таким адресом не зарегистрирована.
|
long vartable_FindNoVar( VAR_TABLE *VT, void * Addr ) |
||
|
|
|
|
|
VT |
– |
указатель на таблицу переменных; |
|
Addr |
– |
адрес переменной. |
Функция осуществляет поиск номера переменной в таблице по ее адресу. Возвращает номер переменной в таблице или -1, если переменная с таким адресом не зарегистрирована.
|
long vartable_PutVariable(VAR_TABLE* VT, void* Addr, int
Env, byte
Type, |
||
|
|
|
|
|
VT |
– |
указатель на таблицу переменных; |
|
Addr |
– |
адрес переменной; |
|
Env |
– |
номер уровня выполнения; |
|
Type |
– |
тип использования переменной; |
|
Handle |
– |
дескриптор распределенного массива при его регистрации; |
|
Tag |
– |
значение дополнительного атрибута переменной; |
|
Info |
– |
указатель на дополнительную информацию; |
|
pfnDestructor |
– |
указатель на деструктор описания переменной. Может быть равен NULL. |
Функция регистрирует новую переменную в таблице. Возвращает номер зарегистрированной переменной.
|
void vartable_VariableDone( VarInfo* Var ) |
||
|
|
|
|
|
Var |
– |
указатель на описание переменной. |
Функция вызывается для деинициализации описания переменной. Устанавливает флаг Busy в 0 и, при необходимости, вызывает соответствующий деструктор.
|
void vartable_RemoveVariable( VAR_TABLE *VT, void * Addr ) |
||
|
|
|
|
|
VT |
– |
указатель на таблицу переменных; |
|
Addr |
– |
адрес удаляемой переменной. |
Функция удаляет описание переменной из таблицы переменных.
|
void vartable_RemoveAll( VAR_TABLE *VT ); |
||
|
|
|
|
|
VT |
– |
указатель на таблицу переменных. |
Функция удаляет описания всех переменных из таблицы переменных.
|
void vartable_RemoveVarOnLevel( VAR_TABLE *VT, int Level ) |
||
|
|
|
|
|
VT |
– |
указатель на таблицу переменных |
|
Level |
– |
номер уровня выполнения |
Функция удаляет описание всех переменных с указанным уровнем исполнения.
|
void vartable_Iterator( VAR_TABLE *VT, PFN_VARTABLEITERATION Func ) |
||
|
|
|
|
|
VT |
– |
указатель на таблицу переменных; |
|
Func |
– |
итерационная функция с
прототипом: |
Функция выполняет однотипную операцию над всеми описаниями переменных из таблицы переменных.
|
void vartable_LevelIterator(VAR_TABLE* VT, int Level, PFN_VARTABLEITERATION Func) |
||
|
|
|
|
|
VT |
– |
указатель на таблицу переменных; |
|
Level |
– |
номер уровня выполнения; |
|
Func |
– |
итерационная функция с
прототипом: |
Функция выполняет однотипную операцию над всеми описаниями переменных указанного уровня исполнения из таблицы переменных.
К модулю выдачи диагностики предъявляются следующие требования. Во-первых, при выдаче сообщения о найденной ошибке должен быть выведен достаточно подробный контекст, в котором данная ошибка была обнаружена. Во вторых, при динамическом контроле необходимо предотвратить выдачу большого количества диагностик об одной и той же ошибке, что неизбежно произойдет при наличии ошибочного оператора в теле цикла. Наконец, необходимо позволить пользователю выводить диагностику, как на экран, так и в файл, с целью последующего анализа.
Модуль диагностики состоит из двух блоков. Блок обработки контекста отслеживает текущий контекст выполнения программы и позволяет получить подробное описание текущего контекста для диагностики. Блок выдачи диагностики занимается выдачей диагностики и фильтрацией однотипных сообщений.
4.4.1 Обработка контекста диагностики
Контекст выполнения программы представляет собой описание всех исполняемых в текущий момент циклов программы вместе со значениями индексов цикла или параллельных задач. Текущий контекст меняется каждый раз, когда начинается или завершается параллельный или последовательный цикл или область задач, начинается выполнение нового витка или новой задачи.
Для описания контекста программы служит структура типа CONTEXT, которая содержит такие данные как уровень вложенности цикла или области задач, номер конструкции, ранг цикла и т.д.:
|
typedef struct _tag_CONTEXT |
|
{ |
|
|
||
|
|
byte |
Rank; |
||
|
|
byte |
Type; |
||
|
|
int |
No; |
||
|
|
byte |
ItersInit; |
||
|
|
long |
Iters[MAXARRAYDIM]; |
||
|
|
s_REGULARSET |
Limits[MAXARRAYDIM]; |
||
|
} |
CONTEXT; |
|
||
|
|
|
|
||
|
Rank |
– |
ранг цикла; |
||
|
Type |
– |
тип конструкции: область задач, параллельный или обычный цикл; |
||
|
No |
– |
уникальный номер конструкции; |
||
|
ItersInit |
– |
определяет, выполнилась ли хотя бы одна итерация цикла или задача из области задач; |
||
|
Iters |
– |
массив текущих значений итерационных перемененных. Для области задач содержит номер текущей выполняющейся задачи. |
||
|
Limits |
– |
массив начальных и конечных значений и шагов приращения итерационных переменных. |
||
Каждая структура типа CONTEXT описывает свой цикл программы или область задач. Последовательный набор таких структур полностью описывает текущий контекст выполнения и порядок вложенности выполняющихся конструкций.
Для хранения последовательности структур CONTEXT в отладчике используется глобальная таблица gContext. При инициализации отладчика, в данную таблицу помещается корневой контекст с номером 0, который соответствует процедуре main() программы.
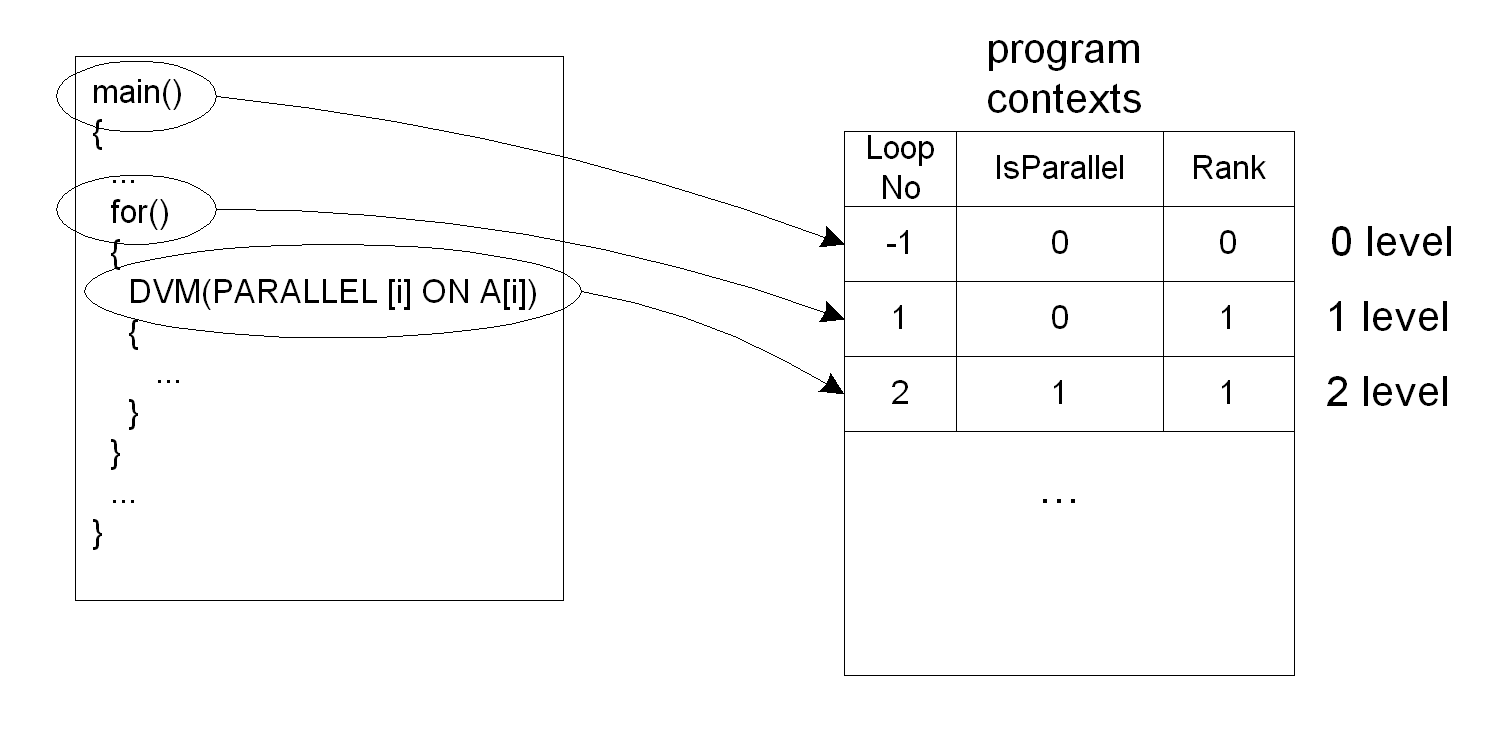
Рис. 3. Представление контекстов выполнения программы
Для работы с контекстом выполнения предназначен следующий набор функций:
|
void cntx_Init(void) |
Функция инициализацирует глобальную таблицу gContext для работы с контекстами. В gContext помещается корневой контекст с номером 0, соответствующий основной ветви программы.
|
void cntx_Done(void) |
Функция разрушает глобальную таблицу gContext и освобождает всю память, занятую для работы с контекстами.
|
void cntx_LevelInit(int No, byte Rank, byte Type, long*
pInit, long* pLast, |
||
|
|
|
|
|
No |
– |
уникальный номер конструкции; |
|
Rank |
– |
ранг цикла; |
|
Type |
– |
тип конструкции: область задач, параллельный или последовательный цикл; |
|
pInit |
– |
массив начальных значений итерационных переменных цикла; |
|
pLast |
– |
массив конечных значений итерационных переменных цикла; |
|
pStep |
– |
массив шагов приращения итерационных переменных цикла. |
Функция заносит в gContext описание нового контекста. Вызывается при входе программы в область задач, параллельный или последовательный цикл.
|
void cntx_LevelDone(void) |
Функция вызывается при завершении текущей исполняющейся конструкции. Удаляет из gContext текущий контекста.
|
void cntx_SetIters( AddrType *index , long IndexTypes[] ) |
||
|
|
|
|
|
index |
– |
массив, содержащий текущие значения итерационных переменных или номер задачи. Размерность массива должна совпадать с рангом текущей конструкции; |
|
IndexTypes |
– |
массив типов индексных переменных. |
Функция изменяет текущие значений итерационных переменных. Вызывается при начале новой итерации цикла или задачи.
|
CONTEXT *cntx_CurrentLevel(void) |
Функция возвращает указатель на структуру, описывающую текущий контекст.
|
CONTEXT *cntx_GetLevel( long No ) |
||
|
|
|
|
|
No |
– |
номер контекста. |
Функция возвращает указатель на структуру, описывающую контекст с указанным порядковым номером.
|
long cntx_LevelCount(void) |
Функция возвращает величину вложенности контекстов исполнения программы.
|
long cntx_GetParallelDepth(void) |
Функция возвращает глубину вложенности параллельных конструкций (параллельных циклов или областей задач) программы.
|
int cntx_IsInitParLoop(void) |
Функция возвращает значение, отличное от 0, если началось выполнения тела текущего параллельного цикла.
|
long cntx_GetAbsoluteParIter(void) |
Функция вычисляет и возвращает как результат абсолютный индекс текущего витка цикла. Для области параллельных задач функция возвращает текущий номер задачи.
|
int cntx_IsParallelLevel(void) |
Функция возвращает значение, отличное от нуля, если в момент вызова функции исполняется хотя бы одна параллельная конструкция.
|
CONTEXT* cntx_GetParallelLevel(void) |
Функция возвращает описание самого вложенного выполняющегося параллельного контекста. Если параллельных контекстов нет, то возвращает NULL.
|
char *cntx_FormatLevelString( char* Str ) |
||
|
|
|
|
|
Str |
– |
указатель на начало буфера. |
Функция формирует в строке по адресу Str описание текущего контекста выполнения программы. Возвращает указатель на конец сформированной строки.
4.4.2 Функции выдачи диагностики
При обнаружении тех или иных ошибок, динамический контроль выводит пользователю соответствующую диагностику. Диагностика выводится на экран или в файл, в зависимости от параметров динамического контроля и режимов работы системы. При многократном обнаружении одной и той же ошибки в разных витках цикла, ошибка выдается только в первый раз. По завершении программы, динамический контроль выдает итоговую информацию обо всех найденных ошибках с числом их повторений.
Общая структура сообщения об ошибке:
(<process number>)<context> File: <file>, Line:
<line>
(<count> times)<error message>
где:
|
<process number> |
– |
номер процессора, на котором произошла ошибка. Номер процессора выводится, только при запуске программы на нескольких процессорах. |
||
|
<context> |
– |
контекст, в котором произошла
ошибка. Контекст может иметь одну из следующих форм: |
||
|
<file> |
– |
имя файла, где произошла ошибка. |
||
|
<line> |
– |
номер строки |
||
|
<count> |
– |
число повторений данной ошибки в данном контексте. Выводится при итоговой выдаче всех найденных ошибок. |
||
|
<error message> |
– |
описание произошедшей ошибки. |
||
Структура, используемая для хранения описания ошибки:
|
typedef struct _tag_ERROR_RECORD |
|
{ |
|
|
||
|
|
int |
StructNo; |
||
|
|
long |
CntxNo; |
||
|
|
char |
Context[MAX_ERR_CONTEXT]; |
||
|
|
char |
Message[MAX_ERR_MESSAGE]; |
||
|
|
char |
File[MAX_ERR_FILENAME]; |
||
|
|
unsigned long |
Line; |
||
|
|
int |
Count; |
||
|
} |
ERROR_RECORD; |
|
||
|
|
|
|
||
|
StructNo |
– |
номер текущего цикла. Равен -1, если нет текущего цикла; |
||
|
CntxNo |
– |
номер текущего контекста исполнения. Вычисляется как cntx_LevelCount() – 1; |
||
|
Context |
– |
строка с описанием контекста; |
||
|
Message |
– |
строка с описанием ошибки; |
||
|
File |
– |
имя файла; |
||
|
Line |
– |
номер строки; |
||
|
Count |
– |
число ошибок данного типа в данном контексте. |
||
Структура таблицы для накопления диагностических сообщений:
|
typedef struct _tag_ERRORTABLE |
|
{ |
|
|
||
|
|
TABLE |
tErrors; |
||
|
|
int |
MaxErrors; |
||
|
|
int |
ErrCount; |
||
|
} |
ERRORTABLE; |
|
||
|
|
|
|
||
|
tErrors |
– |
таблица, содержащая элементы типа ERROR_RECORD; |
||
|
MaxErrors |
– |
максимальное число обрабатываемых ошибок; |
||
|
ErrCount |
– |
текущее число произошедших ошибок. |
||
Прототипы функций для работы с диагностикой:
|
void error_Init(ERRORTABLE* errTable, int MaxErrors) |
||
|
|
|
|
|
errTable |
– |
указатель на инициализируемую таблицу диагностики; |
|
MaxErrors |
– |
максимально число обрабатываемых ошибок. |
Функция инициализирует таблицу диагностики.
|
void error_Done(ERRORTABLE* errTable) |
||
|
|
|
|
|
errTable |
– |
указатель на таблицу диагностики |
Деструктор таблицы диагностики. Освобождает память, занятую под таблицу.
|
ERROR_RECORD *error_Put(ERRORTABLE* errTable, char* File,
|
||
|
|
|
|
|
errTable |
– |
указатель на таблицу диагностики; |
|
File |
– |
имя файла; |
|
Line |
– |
номер строки; |
|
Context |
– |
описание контекста; |
|
Message |
– |
сообщение об ошибке; |
|
StructNo |
– |
номер цикла; |
|
CntxNo |
– |
номер контекста исполнения. |
Функция заносит в таблицу диагностики новое сообщение об ошибке.
|
ERROR_RECORD *error_Find(ERRORTABLE* errTable, char*
File, |
||
|
|
|
|
|
errTable |
– |
указатель на таблицу диагностики; |
|
File |
– |
имя файла; |
|
Line |
– |
номер строки; |
|
Message |
– |
сообщение об ошибке; |
|
StructNo |
– |
номер цикла; |
|
CntxNo |
– |
номер контекста исполнения. |
Функция осуществляет поиск сообщения с заданными параметрами в таблице диагностики.
|
byte error_Message(char* To, ERRORTABLE* errTable, char*
File, |
||
|
|
|
|
|
To |
– |
имя файла, куда выводится диагностика. Если равен NULL, то диагностика выводится в поток stderr; |
|
errTable |
– |
указатель на таблицу диагностики; |
|
File |
– |
имя файла; |
|
Line |
– |
номер строки; |
|
Context |
– |
описание контекста; |
|
Message |
– |
сообщение об ошибке. |
Функция помещает сообщение в таблицу диагностики и выводит его на экран, если данное сообщение отсутствует в таблице диагностики. Иначе, для сообщения только увеличивается счетчик количества сообщений.
|
byte error_Print(char* To, ERROR_RECORD* pErr) |
||
|
|
|
|
|
To |
– |
имя файла, куда выводится диагностика. Если равен NULL, то диагностика выводится в поток stderr; |
|
pErr |
– |
указатель на структуру, описывающую диагностику. |
Функция выдает сообщение в указанный файл.
|
void error_PrintAll( char *To, ERRORTABLE *errTable ) |
||
|
|
|
|
|
To |
– |
имя файла, куда выводится диагностика. Если равен NULL, то диагностика выводится в поток stderr; |
|
errTable |
– |
указатель на таблицу диагностики. |
Функция выдает все диагностические сообщения из таблицы диагностики в указанный файл.
|
void error_DynControl( int code, ... ) |
||
|
|
|
|
|
code |
– |
код ошибки |
Функция выдает диагностику с указанным кодом для модуля динамического контроля.
|
void error_DynControlPrintAll(void) |
Функция выдает все диагностические сообщения модуля динамического контроля.
|
void error_CmpTrace( char *File, unsigned long Line, int code ) |
||
|
|
|
|
|
File |
– |
имя файла трассировки |
|
Line |
– |
номер строки трассировки |
|
code |
– |
код ошибки |
Функция выдает диагностику с указанным кодом для модуля сравнения результатов выполнения при обработке файла трассировки.
|
void error_CmpTraceExt( long RecordNo, char *File, unsigned
long Line, |
||
|
|
|
|
|
RecordNo |
– |
номер записи в файле трассировки |
|
File |
– |
имя файла |
|
Line |
– |
номер строки |
|
code |
– |
код ошибки |
Функция выдает диагностику с указанным кодом для модуля сравнения результатов выполнения.
|
void error_CmpTracePrintAll(void) |
Функция выдает все диагностические сообщения модуля сравнения результатов выполнения.
|
Часть
1 |