|
им. М.В. Келдыша Российской академии наук Бурцев М. С.
Модель эволюционного возникновения целенаправленного
адаптивного поведения.
|


|
yj = Σi wij xi, |
|
где xi – входы j-го нейрона, а wij – его синаптические веса.
Действие, соответствующее выходу, имеющему максимальное значение, выполняется агентом.
Веса нейронной сети агента в течение жизни не изменяются.
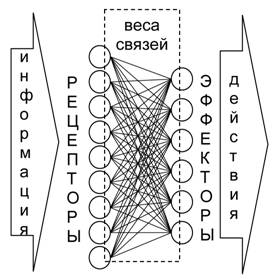
Рис. 4. Схема полной структуры системы управления (нейронной сети) агента.
Популяция агентов эволюционирует во времени за счет изменения структуры и весов синапсов управляющей нейронной сети.
Геном агента S состоит из двух хромосом S = (W, M). Первая хромосома содержит веса синапсов нейронной сети, представленные целыми числами. Наличие или отсутствие модуля в структуре сети определяется значением соответствующего двоичного числа во второй хромосоме.
Изменение генома происходит от родителя к потомку. В результате выработки агентом действия «делиться» появляется потомок. Геном потомка задается при помощи следующего генетического алгоритма:
1. добавить к каждому гену Wi хромосомы, определяющей вес связи, случайную величину x, равномерно распределенную на интервале [-pm, pm];
2. изменить число Mj, определяющее наличие того или иного модуля, на противоположное с малой вероятностью ps.
Моделирование
Модель была реализована в виде компьютерной программы.
Цель компьютерных экспериментов заключалась в том, чтобы показать возможность возникновения иерархии целей у агентов в процессе искусственной эволюции. Так как в нашей модели поведение отдельного агента не изменялось за время его существования, то адаптация к среде проходила на уровне популяции. Естественно рассматривать основную цель популяции как цель выживания в данной среде. Для отдельного агента она будет являться метацелью, определяющей цели его существования – получения энергии и размножения. Но и эти цели в свою очередь могут быть разбиты на подцели, которые позволяют оптимизировать процесс достижения целей высших уровней. Иерархия целей, возникающая в нашей модели, схематично изображена на рисунке 5.
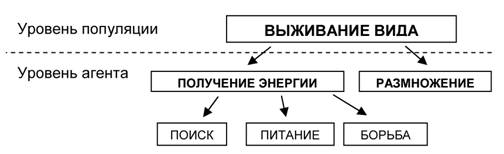
Рис. 5. Иерархия целей, возникающая у агентов в процессе эксперимента
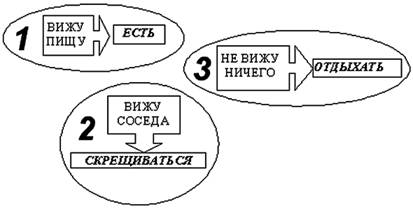
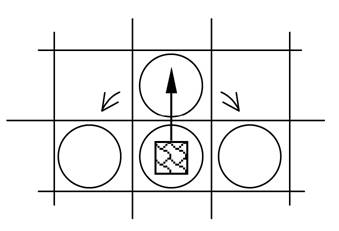
В начале каждого эксперимента мир заселялся популяцией агентов, имеющих минимальный набор рецепторов и эффекторов. Агент начальной популяции мог видеть пищу в той клетке, где он находился, и в клетке находящейся перед ним. А также совершать следующие действия – есть, двигаться и делиться. Веса синапсов были заданы таким образом, чтобы обеспечить агенту два начальных инстинкта – питания и размножения. Если агент видел пищу рядом с собой (в своей клетке), то он должен был выполнять действие «есть», если в соседней клетке, то двигаться в соседнюю клетку; если он не видел ничего, то вызывалось действие «делиться». Очевидно, что агенты начальной популяции обладали лишь примитивной стратегией.
Был проведен ряд компьютерных экспериментов. Результаты одного эксперимента изложены ниже (параметры эксперимента приведены в приложении 1).
На рисунке 6 приведена динамика количества агентов, выполняющих то или иное действие. Этот график позволяет нам провести предварительный анализ эволюции поведения в модели. Так увеличение числа агентов, выполняющих действие "отдыхать", в период t = 12∙106 – 18∙106 приводит к росту общей численности популяции. Это позволяет нам предположить, что эволюция нашла квазиоптимальную стратегию, связанную с действием "отдыхать". После t = 18∙106 численность популяции начинает снижаться, мы можем предположить, что это связано с взаимодействиями между агентами. При увеличении числа агентов, растет вероятность встречи двух агентов, и, следовательно, агенты, нападающие на соседей, быстрее пополняют свою энергию. Это в свою очередь приводит к увеличению их числа. Количество агрессивных агентов растет, и к моменту t = 20∙106 они практически уничтожают "отдыхающих" агентов.
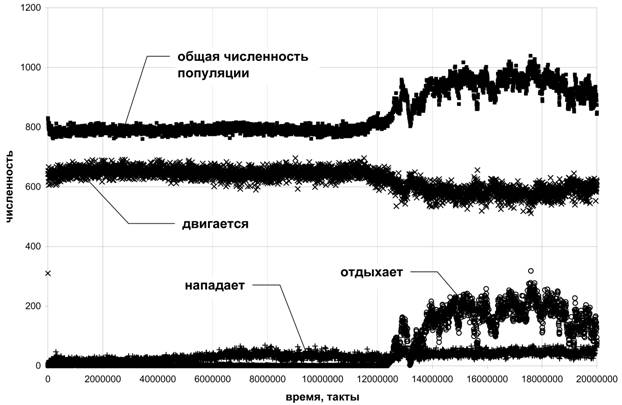
Рис.6. Динамика численности популяции и некоторых действий, выполняемых агентами.
Для более детального анализа воспользуемся картой генома популяции, которая отображает значения весов в системе управления для каждого агента популяции в заданный момент времени (рис. 7). Такая карта позволяет определить различные стратегии поведения присутствующие в популяции. Агентов, имеющих сходные веса, будем объединять в виды.

Рис.7. Карта генома популяции: каждая горизонтальная линия представляет собой набор весов нейронной сети отдельного агента, белый цвет соответствует максимальным значениям весов, а черный минимальным.
Имея значения весов нейронных сетей агентов в популяции для различных моментов времени, мы можем выделить виды и построить их динамику в популяции (рис. 8).
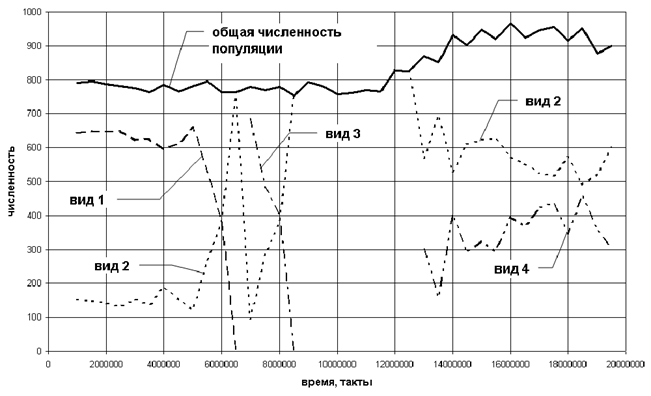
Рис.8. Динамика видов в популяции.
Рассмотрим динамику видов в популяции. На интервале t = 1∙106 – 6∙106 в популяции существует два вида агентов. Анализируя веса для каждого из видов можно определить типы стратегий. Агенты, относящиеся к виду №1, обладают "мирным" поведением, они не нападают на других агентов. Единственным источником энергии для них является пища, случайно появляющаяся в клетках. Агенты вида №2 "всеядны", они могут есть пищу, а также нападать на других агентов. Отметим, что в модели наблюдается колебание отношения этих двух видов. Подобные колебания присутствуют в природных экосистемах, в которых существуют отношения "хищник - жертва". Для описания такой динамики математическая экология использует аппарат дифференциальных уравнений (модель Лотки-Вольтерра), в исследуемой модели появление колебаний является следствием эволюционной самоорганизации.
При t = 6∙106 – 8∙106 вид №2 последовательно вытесняет сначала вид №1, а затем промежуточный вид №3. Затем примерно до 12∙106 такта в популяции доминирует вид №2. Результаты моделирования показывают, что поведение агентов в каком-либо из видов не остается стабильным, а постепенно эволюционирует. Так после 8,5 ∙106 такта агрессивность агентов, относящихся к виду №2, падает и постепенно начинается формирование вида №4. К моменту времени t = 12∙106 мы уже можем четко выделить вид №4. Агенты вида №4 обладают агрессивной стратегий и способностью экономить энергию, выполняя действие "отдыхать". В период t = 12∙106 – 20∙106 снова наблюдаются колебания, только теперь в качестве "жертв" выступают агенты вида №2, а "хищников" вида №4.
Рассмотрим, как происходит формирование иерархии целей в экспериментах с моделью.
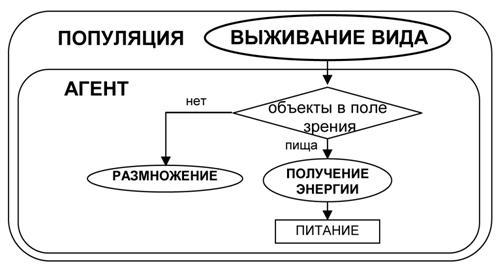
Рис.9. Дерево условий для управления выбором подцелей агента начальной популяции.
Поведение агентов начальной популяции (имеющих минимальный набор рецепторов и эффекторов) можно схематично представить в виде блок-схемы (рис. 9). Агенты начальной популяции обладают примитивной стратегией, в которой учитывается только наличие пищи в поле зрения.
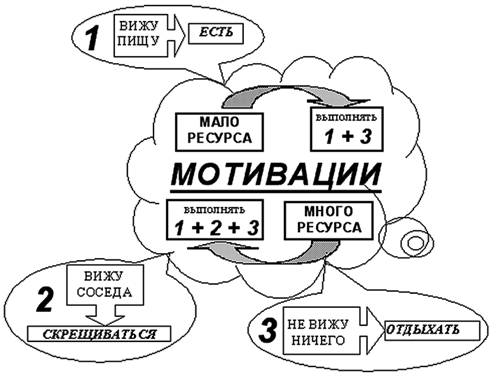
В ходе эволюции поведение агентов усложняется. Стратегия агентов на 5∙106 такте (вид №2) может быть представлена в виде схемы, показанной на рис. 10 (см. также таблицу приложения 2). Видно, что из примитивной стратегии, заданной нами для агентов начальной популяции (рис. 9), развивается достаточно сложное поведение, которое можно назвать целенаправленным. Так первоначальный «инстинкт» агента, направленный на получение энергии оптимизируется за счет появления еще одного уровня подцелей, направленных, соответственно: на само питание, на поиск пищи, борьбу. Для эффективного управления поведением, имеющим подобную многоуровневую иерархию целей, необходимо иметь информацию о том, какие цели являются предпочтительными для агента в данный момент времени. Для этого агенту необходимо знать не только состояние окружающей его среды, но и своего энергетического ресурса. В модели эта информация может быть получена от входов, связанных со значением и изменением ресурса за последний такт. Значения на этих входах могут быть интерпретированы как мотивации к выбору того или иного типа поведения. Так, большое значение внутреннего ресурса может рассматриваться как мотивация к размножению. Если ресурса много, то отсутствие раздражителей во внешней среде приводит к делению агента, а если мало, то к поиску пищи. Изменение внутреннего ресурса используется агентами как мотивация к нападению на впереди стоящего агента. Если эта мотивация положительна, т.е. предыдущее действие привело к увеличению энергии, то агент нападает на соседа. Если данная мотивация отрицательна, то атака прекращается.
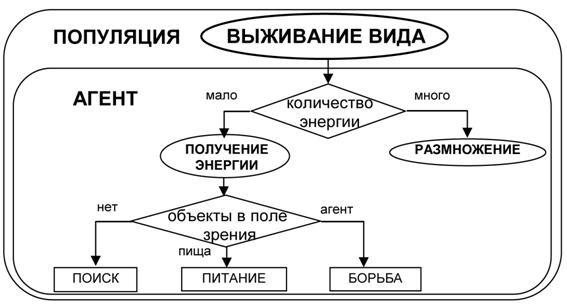
Рис.10. Дерево условий для управления выбором подцелей
Заключение
Проведенное моделирование показывает, что в процессе искусственной эволюции в популяции агентов вырабатывается поведение, которое можно рассматривать как поведение, управляемое в соответствии с некоторой иерархией целей. Причем эта иерархия постепенно усложняется в процессе эволюции. Формирование иерархии целей приводит к потребности в механизме выбора текущих подцелей. В качестве такого механизма выступают мотивации.
Результаты экспериментов также демонстрируют, что в рассматриваемой модели возможно возникновение и одновременное существование агентов использующих различные стратегии поведения, притом, что изначально популяция однородна. Можно интерпретировать это как возникновение и взаимодействие видов.
Текущая модель позволяет исследовать влияние неоднородности распределения пищи на поведение и видообразование в популяции. Так предварительные результаты показывают, что неоднородное распределение приводит к увеличению числа подвидов. Также при помощи модели можно рассмотреть вопросы, связанные с эволюционным обучением и сохранением знания на уровне популяции в нестационарных условиях (при изменении количества пищи во времени).
На следующем этапе исследований в модель планируется ввести обучение агента в течение жизни и возможность усложнения нейронной сети агентов в процессе эволюции. Эти усовершенствования позволят изучить зависимость эволюционных процессов от обучения, а также дадут возможность возникновения сложных иерархий в поведении.
Благодарности
Автор благодарен В.Г. Редько за ряд полезных консультаций.
Список литературы
1. Artificial Life // Langton С., The Proceedings of an Interdisciplinary Workshop on the Synthesis and Simulation of Living Systems, Redwood City CA: Addison-Wesley, 1989.
2. Artificial Life II // Langton C., Taylor C., Farmer D., and Rasmussen S., Artificial Life II, Santa Fe Institute Studies in the Sciences of Complexity, X, Reading, MA: Addison-Wesley, 1992.
3. Nolfi S., Parisi D. Learning to adapt to changing environments in evolving neural networks // Adaptive Behavior, 5, 1, 1997, pp. 75-98 [http://gral.ip.rm.cnr.it/nolfi/papers/nolfi.changing.pdf]
4. Tesfatsion L. How Economists Can Get Alife // W.Brian Arthur, Steven Durlauf, and David Lane, Santa Fe Institute Studies in the Sciences of Complexity, XXVII, Redwood City CA: Addison-Wesley, 1997. [http://www.econ.iastate.edu/tesfatsi/surveys.htm]
5. Бурцев М.С., Гусарев Р.В., Редько В.Г. Модель эволюционного возникновения целенаправленного адаптивного поведения 1. Случай двух потребностей. М.: ИПМ РАН, (2000). [http://www.keldysh.ru/pages/BioCyber/PrPrint/PrPrint.htm]
6. Турчин В.Ф. Феномен науки. Кибернетический подход к эволюции. М.: ЭТС, (2000). [http://refal.net/turchin/phenomenon]
Приложение 1
Параметры эксперимента
Размер мира: 100 на 100 клеток
Численность начальной популяции: 1000
Вероятность возникновения пищи в клетке: 3∙10-4
Максимальное значение веса нейронной сети: 1000
Максимальное изменение веса при мутации: pm = 20
Вероятность мутации модуля: ps = 0,01
Максимальное значение внутреннего энергетического ресурса: Rmax = 5000
Энергетическая ценность пищи: k5 = 500
Энергетические затраты на деление: k6 = 20
Энергетические затраты на движение: k2 = 20
Энергетические затраты на питание: k4 = 20
Энергетические затраты на поворот: k3 = 10
Энергетические затраты на отдых: k1 = 5
Энергетические затраты на нападение: k7 = 30
Энергетические затраты на защиту: k8 = 20
Приложение 2
Таблица. Стратегии агентов на 5∙106 такте
|
|
Вид 1 |
Вид 2 |
|
Мало энергии (R = 0.02 Rmax) |
|
|
|
Ничего не видно |
двигаться вперед |
двигаться вперед |
|
Еда рядом |
есть |
есть |
|
Еда впереди |
двигаться вперед |
двигаться вперед |
|
Агент впереди |
поворачивать налево |
поворачивать налево |
|
Еда слева/справа |
поворачивать налево/направо |
поворачивать налево/направо |
|
Агент слева/справа |
двигаться вперед |
двигаться вперед |
|
Среднее количество энергии (R = 0.05 Rmax) |
|
|
|
Ничего не видно |
двигаться вперед |
двигаться вперед |
|
Еда рядом |
есть |
есть |
|
Еда впереди |
двигаться вперед |
двигаться вперед |
|
Агент впереди |
поворачивать налево |
ударить/поворачивать направо |
|
Еда слева/справа |
поворачивать налево/направо |
поворачивать налево/направо |
|
Агент слева/справа |
двигаться вперед |
двигаться вперед |
|
Много энергии (R = 0.96 Rmax) |
|
|
|
Ничего не видно |
двигаться вперед |
двигаться вперед |
|
Еда рядом |
есть |
делиться |
|
Еда впереди |
делиться |
двигаться вперед |
|
Агент впереди |
поворачивать налево |
ударить |
|
Еда слева/справа |
поворачивать налево/направо |
поворачивать налево/направо |
|
Агент слева/справа |
двигаться вперед |
двигаться вперед |