ПЕДАНТ. Архитектура многопроцессорного комплекса
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

|
Память данных и команд |
|
Кольцо виртуальных
процессоров. |
Здесь:
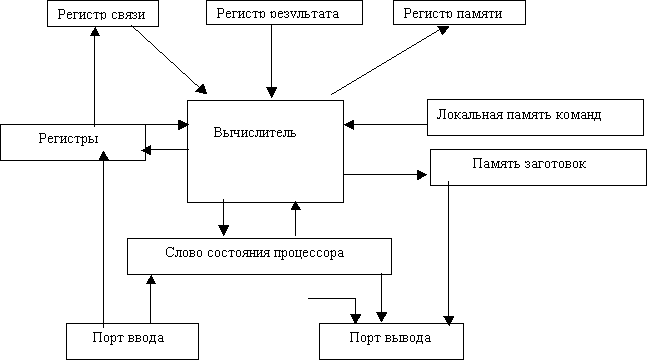
Физические процессоры – совокупность процессоров. Их порты ввода и вывода связаны с кольцом виртуальных процессоров, регистры памяти - с устройством выбора процессора для обмена, а регистр результата с памятью. Регистр связи получает значение непосредственно от устройства выбора.
Выбор
процессора для обмена с памятью – устройство для разрешения конфликтных ситуаций, возникающих при
одновременном обращении к памяти или другому процессору из нескольких процессоров
одновременно.
Память данных и команд – совокупность памятей, включая кэш памяти.
Синхронизатор – память, сохраняющая запросы к основной памяти, которые не были реализованы из-за отсутствия объекта в кэш или из-за несоответствия тегов, либо значения, передаваемые виртуальным процессорам, которым в момент передачи не соответствовали физические. Размер памяти равен количеству виртуальных процессоров.
Кольцо виртуальных процессоров – кольцевая память, каждый элемент которой содержит виртуальный процессор. Виртуальные процессоры заносятся в кольцо через порты вывода физических процессоров как результат выполнения команд, передающих данные. Напомним, что в этом случае передаются данные треду, для выполнения которого и выделяется виртуальный процессор.
Контроль присутствия – устройство, позволяющее определить, соответствует ли в данный момент физический процессор виртуальному, которому передается значение. При несоответствии значение попадает в память синхронизации.
Рассмотрим теперь более подробно работу каждого из
устройств.
6. Выбор процессора при обращении к
памяти.
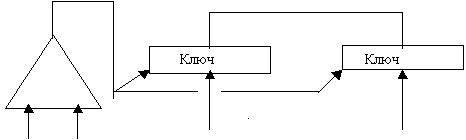
В многопроцессорных системах принципиальной является проблема разрешения конфликтной ситуации при обращении к одной и той же ячейки памяти одновременно из разных процессоров. Ниже рассматривается один из вариантов решения этой проблемы. Назовем такое устройство “выбор с привилегиями”. Устройство состоит из двух частей – выбор номера процессора и ключей, позволяющих по этому номеру выбрать соответствующий регистр памяти.
![]() К памяти
К памяти
Номера процессоров. Регистр памяти. . . . Регистр памяти.
Здесь “Номер процессора” - виртуальный номер процессора, записанный в слове состояния физического процессора. Количество номеров, из которых производится выбор, очевидно, равно числу физических процессоров. Возможны различные схемы выбора, например, шкала номеров или древовидная структура из компонент, разрешающих конфликтные ситуации, или их сочетание. Критерием выбора является, конечно, скорость выбора. После выбора номера содержимое соответствующего регистра памяти передается памяти, а сам регистр - сбрасывается.
Устройство выбора задает очередность обращения
процессоров к памяти. Задержка из-за очереди увеличивает время выборки. Однако,
это время можно уменьшить за счет
разбиения памяти на блоки, в которых адреса группируются, например, по модулю
(четные-нечетные и т. п.). В этом случае устройство выбора
тиражируется в соответствии с количеством модулей, допуская обращение к памяти
одновременно в нескольких модулях.
7. Память данных.
Будем считать, что память
данных состоит из нескольких блоков с непересекающимися адресами. Рассмотрим
один из возможных способов организации такой памяти – память с кольцевым буфером.
К памяти для синхронизации.

Блок основной
памяти. Блок основной
памяти. Блок основной
памяти.
Кэш Кэш Кэш![]()
![]()
![]()
![]()
![]()
 .
.
![]()
К памяти для синхронизации
Ответ процессорам. и процессорам
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
От блоков выбора процессора при обращении к
памяти.
Когда при обращении к кэш памяти происходит “промах”, то есть объект в кэш отсутствует, то команда обращения к памяти передается в кольцевой буфер. В нем команда циркулирует до тех пор, пока необходимый блок памяти не завершит предыдущее задание и не начнет выполнять данную команду. Ответы из блоков также попадают в кольцевой буфер и из него подкачиваются в кэш.
Команда обращения к кэш может быть как выполненной,
так и не выполненной. Последнее бывает в двух случаях – несовпадение тегов и
“промах”. И в том и в другом случае происходит прерывание выполнения треда
командой ответа с одновременной записью запроса в память синхронизации.
8. Синхронизатор.
По-существу,
синхронизатор это специальная память, в которой хранятся неудовлетворенные
запросы при обращении процессора к основной памяти и при передаче значения
другому процессору. Количество объектов в памяти равно числу виртуальных
процессоров. Неудовлетворенный
запрос записывается в тот объект памяти, номер которого равен номеру
процессора, выдавшего запрос или не получившего значение.
Синхронизатор используется для реализации запросов при изменении ситуация в памяти. Рассматриваются два варианта изменения – подкачка после “промаха” и перемена тега. При изменении ситуации происходит обращение ко всем объектам синхронизатора, в которых хранящийся запрос имеет адрес, равный адресу того объекта в основной памяти, который был подкачен или у которого изменился тег. Удовлетворенные таким образом запросы передаются в кольцо виртуальных процессоров процессорам с соответствующими номерами.
Синхронизатор
можно рассматривать как полуассоциативную память, в которую записывается по
адресу, а выбирается по ассоциации.
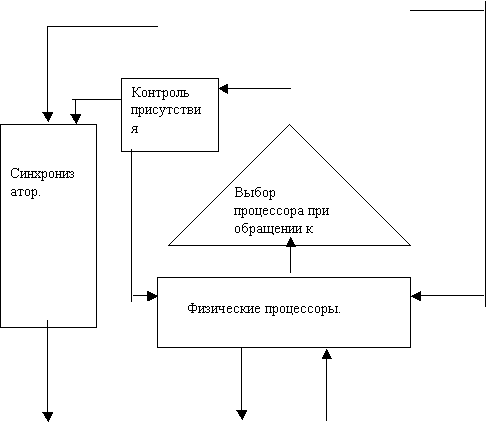
9. Кольцо виртуальных процессоров.
Кольцо
виртуальных процессоров – это кольцевая память, объектами которой являются
виртуальные процессоры. Каждый такт изменяет положение виртуальных
процессоров на одну позицию. На рисунке кружочками обозначены виртуальные
процессоры.
Снхронизатор. Физические процессоры.
![]()
![]()
![]()

 .
.
![]()
![]()
![]()
Физические процессоры связаны с кольцом через порты ввода и вывода.
Каждому занятому физическому процессору соответствует в кольце его виртуальный.
Виртуальные процессоры могут находиться в одном из следующих четырех состояний:
- свободен,
- поиск свободного физического процессора,
- ожидание информации от синхронизатора,
- занят физическим процессором.
В свою очередь порт ввода может находиться в состоянии:
- свободен,
- захвачен.
Состояниями порта вывода могут быть:
-
свободен, - ожидание свободного виртуального процессора
для передачи данных,
- ожидание виртуального процессора, соответствующего по номеру текущему физическому, для сохранения состояния в случае прерывания исполнения треда или его освобождения
Передача данных между физическими процессорами и находящимися в кольце виртуальными происходит в соответствии с их состояниям в момент совпадения позиции кольца с позицией процессора.
При передаче данных от синхронизатора рассматривается готовность объекта с номером, равным номеру виртуального процессора, находящегося в позиции синхронизатора, и состояние самого этого процессора. Передача данных, очевидно, меняет состояние.
Время поиска в кольце виртуальных процессоров процессора, находящегося в нужном состоянии, пропорционально количеству позиций кольца. Нетрудно видеть, что можно уменьшить в несколько раз длину кольца при сохранении количества виртуальных процессоров. Для этого нужно лишь заменить одно кольцо несколькими, усложнив схемы выбора. Ниже приведен пример двойного кольца.
Порт ввода. Порт вывода.
![]()
![]()
![]()
![]()
![]()




![]()
Кольцо 1
Кольцо 2
Примеры и приемы программирования.
Все приведенные примеры записываются на языке ассемблера. Поля в предложениях ассемблера называются:
Опер – операция,
И – индикатор способа адресации,
Р – идентификатор регистра,
Адр- поле адреса.
1. Перемножение матриц.
Рассмотрим следующий пример.
MM,NN,RR: array[1..20]
of integer;
Sum: integer;
For I in 1..20
Loop
For j in 1..20
Loop Sum:=0;
For k in 1..20
Loop
Sum+=MM[i,k]*NN[k,j]
End loop;
RR[i,j]:=Sum
End loop
End loop
Опер И Р Адр Комментарий
rdv l C 19 19 => C
gener c end Конец перемножения матриц. à
mult l
C 20
wtv r C D i*20 => D
rdv l C 19
gener c Line
à
wtv r C E j => E
rdv l C 19
k => C
prnm r H Виртуальный номер процессора => H
gener c Summa à
wrv r C F
add r F D i*20+k => F
rdv a F
MM
wrv r S F MM[j,k] => F
mult l C 20 k*20 => C
add r C E k*20+j => C
rdv a C NN NN[k,j] => S
mult r S F
conn r S H Передача ММ[i,k]*NN[k,j] процессору с
номером в H
stop
Summa rdv l G 20 В G количество слагаемых.
rdv l S 0
add p S G В S накапливается сумма значений из
регистра связи.
add r E D i*20+j => E
wrv a E RR
Запись значения в RR[I,j]
stop
Line stop
End stop
В приведенном примере строки из пробелов отделяют части программы, соответствующие тредам. Стрелки à указывают на продолжение треда.
2. Упорядочение массива целых чисел.
Рассмотрим пример, демонстрирующий защиту объекта, который изменяется одним тредом, от несвоевременного доступа со стороны другого треда. С этой целью рассмотрим задачу упорядочения массива целых чисел методом пузырька. Допустим, что задача решается независимо, но одновременно сразу несколькими процессорами, и используется стандартный алгоритм сортировки. Понятно, что задача будет решаться быстрее, поскольку процессоры будут помогать друг другу. Для определенности выберем 10 виртуальных процессоров и массив MM из 1000 слов по два байта.
Rdv l D
1 D = 0 - признак упорядоченности
Rdv l C 9
Gener c
End Генерация 10 тредов à
Cycl eq l D 0
cond c Stp
Окончание сортировки
rdv l D 0
rdv l E
0 E – номер элемента в массиве
rdup a E MM Блокировка обращения из другого треда
wrv r S F В F – левый элемент пары
Chck add l
E 2
rdup a E MM
wrt r S G В G – правый элемент пары
le r F G
cond c Right
wtv r G H Обмен значениями
wrv r F G
wrv r H F
rdv r D 1 Сортировка не закончена
Right sub l
E 2
rdv r S F
wrup a E MM
add l E 4
wrv r F G Новое значение левого элемента пары
lt l E 2000
cond c Chck
br c Cycl
Stp stop
End stop
В этом примере тред, содержащий команду gener, передает данные
десяти другим тредам, каждый из которых на своем собственном процессоре
выполняет сортировку массива. Здесь тред – целая программа со своими циклами.
3. Вызов процедуры.
Вызов процедуры передачей данных отличается тем, что любая передача параметра приводит к началу выполнения треда в вызываемой программе. Второе отличие – процедуры должны быть реентерабельными. Это означает наличие собственной локальной памяти для каждого вызова процедуры. Если это условие не соблюдено, то потребуется дополнительная синхронизация для установления последовательности вызова процедур.
Очевидно также, что в случае процедуры-функции команда, принимающая значение, должна иметь индикатор w, чтобы обеспечить синхронизацию операндов. Кроме того, необходимо обеспечить восстановление тех значений регистров, которые они имели до обращения к процедуре.
Вообще говоря, команды, реализующие вызов и возврат из процедуры, должны выполнять соглашение о связи вызывающей и вызываемой процедур. Один из возможных вариантов такого соглашения реализован в приведенном ниже примере. В дальнейшем будем считать, что
- программа расположена в основной памяти,
- все процедуры адресуются с нуля, то есть значение базы (регистр A) процедуры устанавливается на ее начало,
- адреса меток задаются по отношению к началу процедуры, а адрес самой процедуры устанавливается загрузчиком по отношению к началу памяти,
- при каждом вызове процедуры ей выделяется локальная память данных, база которой находится в регистре D,
- локальная память начинается с области сохранения регистров, за которой следуют дескриптор возврата и дескриптор параметров,
- параметр передается по значению командой передачи данных треду.
Рассмотрим
следующий простой пример.
Proc RlSign(x,y) returns integer
If x*y>0
then return 0
else return 1
end if;
… p*RlSign(m,n) … (* вызов RlSign *)
Пусть
аргумент m записан в локальной памяти вызывающей
процедуры по адресу ММ, аргумент n – по
адресу NN, а p –
по адресу PP. Как обычно, локальная память данных в
вызывающей процедуре базируется регистром B.
Будем считать, что размер слова в этой памяти равен четырем байтам.
Локальная
память данных начинается областью сохранения регистров – C,D,E,F,G,H,S, состоящей из семи слов. За ней следуют дескриптор возврата и шаблон дескриптора
передачи параметров. В шаблоне в момент передачи параметра первое слово
заменяется адресом входа, по которому этот параметр передается.
Ниже
приведены фрагменты текста программы.
Процедура RlSign.
RlSign
proc
RlSign#1 nop
RlSign#2 mult
w WRlSign WRlSign– объект для синхронизации,
который
находится в локальной
gt
l S 0 памяти данных процедуры RlSign.
pop
с B 0 Восстановление регистров
rdv l
S 0
cond d D 0 D снова
указывает на начало области
rdv l
S 1
br d D
0
endp
Передача
параметров и обращение к процедуре RlSign.
push c D 0 Сохранение регистров
rdv l S
Rt
call c D 28 Запись дескриптора возврата
rdv l S RlSign База процедур
par c D 40 Запись шаблона для дескриптора параметра
rdv l S
RlSign#1
wrv c
D 40
rdv a
MM
fork d D 40
Передача первого
параметра
rdv l S
RlSign#2
wrv c
D 40
rdv a NN
fork d D 40 Передача второго параметра
rdv a PP
Rt mult w Wmlt Wmlt – объект для синхронизации, который
расположен а локальной памяти
данных.
…
Заключение.
Предлагаемая
архитектура многопроцессорного комплекса решает большинство проблем,
возникающих при совместной работе нескольких процессоров над одной задачей в
стиле fine grain параллелизма. Заметим, что используемая тредовая
модель вычислений позволяет рассматривать в качестве треда любую часть программы от нескольких команд до отдельных процедур.
На наш взгляд существенным в предлагаемой архитектуре является использование
специальной памяти для синхронизации, которая значительно облегчает решение таких проблем как попытка
использование значения до его получения, ожидание подкачки из основной памяти в
кэш или передачи значения от одного процессора другому. Использование очереди
заготовок существенно ускоряет переключение физического процессора при замене
тредов. В настоящее время проводится анализ работы системы на программной
модели. Анализ результатов, по-видимому, приведет к дальнейшему усовершенствованию
системы.
Литература.
1. Dennis, Jack B. Data flow supercomputers.
Computer 13, 11 (Nov. 1980).
2. Gard, J. R., Kirkham, C. C., Watson, I.
The Manchester prototype dataflow computer.
CACM 28, 1 (January 1985).
3. G. M. Papandoupulos, K. R. Traub.
Multithreading: A Revisionist
View of Dataflow
Architectures.
ACM SIGARCH V. 19, N 3 (May
1991)
4. R. Alverson, D. Callahan, D. Cummings, B.
Koblenz,
A. Portenfield, B. Smith.
The Tera computer system.
Proceedings of the 1990 ACM
International
Conference on Supercomputing, june
1990.
5. В.М. Михелев
ПРОК Архитектура многопроцессорного
комплекса, препринт ИПМ им. Келдыша РАН,
2000, N 59.
6. Cvetanonic.
Alpha Server 4100 Performance Characterization.
Digital Technical Jornal 8(4) 1996.