Аннотация
Вводится понятие логической энтропии как меры неопределенности и сложности информационных
моделей, описываемых булевскими функциями. Приводятся содержательные интерпретации логической
энтропии. Демонстрируется отличие логической энтропии от энтропии Теории информации.
Выделяется класс физических систем, энтропия которых совпадает с энтропией их информационных
моделей.
Abstract
It is entered notion of logical entropy as measures to uncertainties and difficulties
of the information models, described logical functions. Profound interpretation to logical
entropy is given. It is demonstrated difference between the logical entropy and entropy of
Theory of information. Stands out the class of the physical systems, entropy which comply
with entropy their information models.
De non apparetibus
et non existentibus eadem est ratio.
О том, чего не видно и о том,
чего не существует,
судят одинаково. (лат.)
Введение. Содержательное обоснование логической энтропии, как меры неопределенности
информационных моделей дано в [1], где физические системы представляются
логическими функциями, аргументы которых используются для кодирования объектов.
В результате объекты в информационных моделях кодируются единичными
означиваниями логических функций. И если различные означивания приводят к
логически эквивалентным функциям, то они определяют одну характеристическую функцию
некоторой совокупности объектов.
Более формально это
выглядит так.
Пусть булевская функция f(x1, x2, …, xn) служит информационной моделью
физической системы. Ее объекты кодируются наборами вида (s1, s2, …, sn) признаков, si Î {0, 1}, i = 1, 2, …, n, при котором функция f истинна.
Тем самым, число различных объектов не превосходит мощности множества
{(s1, s2, …, sn)| f(s1, s2, …, sn) = 1}
единичных означиваний функции f.
В [1] введено понятие
неопределенности физической системы  (x1, x2, …, xn), определяемой переменными x1, x2, …, xi, i (x1, x2, …, xn), определяемой переменными x1, x2, …, xi, i  n. Аналогично определяется неопределенность ее информационной
модели f(x1, x2, …, xn),
определяемой переменными x1, x2, …, xi, i n. Как будет показано неопределенность функции f(x1, x2, …, xn), определяемая переменными x1, x2, …, xi, обладает следующими свойствами. n. Аналогично определяется неопределенность ее информационной
модели f(x1, x2, …, xn),
определяемой переменными x1, x2, …, xi, i n. Как будет показано неопределенность функции f(x1, x2, …, xn), определяемая переменными x1, x2, …, xi, обладает следующими свойствами.
1.
Ее
значение зависит от числа k подфункций, которые получаются в
результате разложения функции по переменным x1, x2, …, xi.
При увеличении k (при прочих равных условиях)
неопределенность возрастает.
2.
Неопределенность
определяется относительными долями мощностей соответствующих множеств å1, å2, .., åk означиваний переменных x1, x2, …, xi,
приводящих к эквивалентным функциям. Если все множества å1, å2, .., åk одинаковы и доля каждого равна 1/k, то неопределенность монотонно возрастает с ростом k.
3.
При
переходе от означивания переменных x1, x2, …, xi, к означиванию переменных x1, x2, …, xi, xi+1 их
неопределенность зависит от неопределенности, определяемой переменными x1, x2, …, xi.
Последнее свойство легко
объяснимо с содержательной точки зрения, если заметить, что между аргументами
функции f могут существовать зависимости,
когда значения одних переменных в той или иной степени определяют значения
других. Например, в случае функциональной зависимости одному значению некоторых
переменных соответствует в точности одно значение других. И тогда порядок
означивания существенно определяет последовательность разбиений объектов на
классы. В результате, свойство аддитивности неопределенности нарушается.
1. Неопределенность булевских функций. Определим понятие энтропии логической
функции и установим ее связь со структурой функций. Формальное определение
логической энтропии мы введем, основываясь на следующем.
Пусть f(У, w) есть булевская функция, множество У
ее аргументов назовем входными переменными и w – выходными. При определенных значениях
sY ее входных переменных и sw - выходных f(sY, sw)
= 1. Тем самым, функция f определяет отображение, ставящее в
соответствие входным значениям - выходные. В общем случае, один входной кортеж
определяет несколько выходных.
Напомним, что логическая
функция f(Y, w)
представляет вычислимую двоичную функцию j(Y) если: f(Y, w) = 1 ój(Y) = w.
Назовем кортеж sy означиваний (не обязательно всех)
входных переменных y y-набором. Тем
самым, для логической функции f(Y, w), представляющей вычислимую функцию,
верно, что всякий ее y-набор определяет некоторое множество w-наборов.
Нам потребуется следующее
определение.
Бинарной программой pf для логической функции f(x1, x2, …, xn) называется ор-дерево с единственным
корнем (истоком), которому приписана
функция f(x1, x2, …, xn),
и двумя висячими узлами, одному из которых приписано значение 1 (1-сток), другому 0 (0-сток), а дуги помечены литерами xi
или`xi,
i =
1, 2, …, n. Если два узла сети соединяются путем,
дуги которого не содержат ортогональных меток, то назовем его проводящим. Каждый узел дерева достижим
из истока. Проводящий путь, дуги которого помечены метками, образующими
множество {xj1s1, xj2s2, …, xjmsm} литер, где s1, s2,
…, sm Î {0, 1}, назовем определяющим это множество.
Внутренние узлы и дуги
программы помечены следующим образом.
1.
Каждой
дуге приписана в точности одна литера xi
или`xi,
i =
1,2, …, n.
2.
Из
каждого внутреннего узла ведут в точности две дуги, которым приписаны литеры xi и`xi, i = 1,2, …, n.
3.
Если
в узел N ведет проводящий путь, дуги которого
помечены метками xj1s1, xj2s2, …, xjmsm , то этому узлу приписана функция,
которая получается из исходной в результате присваивания переменным xj1, xj2, …, xjm
значений соответственно s1,
s2, …, sm. Узлы, соответствующие эквивалентным функциям, склеиваются.
При этом узлу приписан в точности один представитель класса эквивалентности.
4.
Для
каждого из 2n двоичных наборов sх переменных имеется путь проводящий из истока либо в 1-сток
либо в 0-сток, множество меток дуг которого покрывается компонентами sх.
Так как логическая
функция однозначно характеризуется перечислением своих 1-проводящих путей, то
будем мыслить бинарные программы, состоящими лишь из 1-проводящих путей. Тогда
бинарная программа представляет собой двухполюсник с истоком, которому
приписана логическая функция f, и стоком, который помечен 1.
Пусть функция f(Y, w) представляет вычислимую двоичную
функцию j. В бинарной программе pf каждое вычисление j(sY) = sw представлено единственным путем из
истока в сток. Ограничимся рассмотрением программ, для которых все пути из
истока на начальных отрезках содержат дуги, помеченные литерами, образованными
только из входных переменных y, и после этих отрезков дуг с такими
метками не встречается. Такие бинарные программы назовем однородными.
Введем еще одно определение.
y-сечением однородной бинарной программы
назовем множество всех ее узлов, которыми завершаются все пути, начинающиеся в
истоке и дуги которых помечены литерами, образованными лишь из переменных некоторого
подмножества y входных переменных.
Применительно к
вычислениям, реализуемым бинарными программами, можно говорить о
неопределенности выходных значений от входных. Действительно, если задан y-набор sy, то он задает единственный путь
программы pf из истока в некоторый узел N. Нам удобно мыслить узел N как некоторый промежуточный вычислитель. Он может соединяться со стоком
несколькими путями, каждый из которых характеризуется собственными выходными
значениями. И только по входным значениям нельзя определить, какой именно
выходной вектор появится на выходе такого вычислителя. В связи с этим можно
говорить лишь о различении множеств выходных векторов, которые определяются различными
узлами y-сечения.
Мы рассмотрим несколько
различных подходов к вычислению неопределенности и дадим их содержательные
интерпретации. Это прояснит связь настоящего подхода с традиционным в Теории
информации.
В последующем, главным
образом мы будем рассматривать логические функции, представляющие всюду
определенные вычислимые функции. Во избежание путаницы, мы всегда будем указывать,
какие логические функции рассматриваем, если это не вытекает из контекста.
Очевидно, что если логическая функция
f(Y, w) представляет
всюду определенную вычислимую функцию j(Y), то при любом y-наборе
sy функция f(sy, w) не
является тождественным нулем. В этом случае j(sy) = {sw: f(sy, sw) = 1 при любых подстановках на места
не означенных переменныъ}.
Если полагать, что
входные переменные независимы и их значения 0 и 1 одинаково возможны, то можно
говорить о неопределенности зависимости выходных значений от входных, как о
характеристике y-сечения. Действительно, чем меньше y-сечение, тем больше определенность,
какой промежуточный вычислитель вычислеят выходные значения. В предельном
случае, когда сечение содержит в точности один узел, при любом входном векторе
все вычисления осуществляются одним вычислителем. Если сечение имеет 2|y| узлов, то неопределенность максимальна, так как
имеется возможность выбора из наибольшего числа доступных вычислителей.
Выберем в качестве
показателя неопределенности выходных
значений в зависимости от входных y, двоичный логарифм от числа узлов y-сечения программы pf. Полагаем, что все входные
переменные y независимы, y-сечение состоит из k узлов, каждый его узел соединен с истоком одним и тем
же числом`t путей и
число всех путей программы из истока в y-сечение равно t.
Справедливо равенство log k = log (t /`t ). Доля путей, ведущих в один узел y-сечения среди всех путей программы pf из истока в y-сечение равна py =`t /t. Тогда log k = - log py. Если предположить, что доли py(i) путей,
ведущих в i-ый узел y-сечения программы pf различны, наложив требование, чтобы
выполнялось равенство åi=1,k py(i) = 1, то получим более общую формулу - åi=1,k py(i) log py(i), которая
выражает неопределенность означенных переменных. Еще раз подчернем, что
рассматриваемое сечение определяется в результате означивания подмножества
входных переменных y. Из этого следует, что
log
k  - åi=1,k py(i)
log py(i). - åi=1,k py(i)
log py(i).
Доля py(i) в общем
случае зависит от способа построения бинарной программы выше y-сечения. Чтобы в этом убедиться,
рассмотрим два примера.
Пример 1. Пусть
функция f(x1, x2, y1, y2, z) =
(x1`x2 Ú`x1`x2)(y1y2Ú`y1`y2)f1(z)Ú(`x1x2)(y1y2Ú`y1`y2)f1(z)Úx1x2(`y1y2Úy1`y2)f2(z).
Здесь z – это не пустой набор переменных
отличных от x1,x2,y1,y2. Начальный фрагмент бинарной программы для этой
функции приведен на рис.1. Здесь для каждого узла вначале указан его номер,
затем (в скобках) - доли путей, ведущих из истока в этот узел, от числа всех
приведенных путей. Так в узел 1
ведут два пути, которые получаются в результате означиваний переменных {x1 = 1, x2 = 0} и {x1 = x2 = 0}. На рис. 1 этим путям соответствует
одна дуга, помеченная {x1`x2}È{`x1`x2}. Соответствие между меткой дуги и соответствующими
означиваниями очевидно. Всего же путей из истока, которые получаются в результате
означиваний переменных x1 и x2, четыре. Следовательно, доля всех путей из истока в
узел 1 среди всех путей равна
½. Аналогично вычисляются доли путей, ведущие в остальные узлы.
Построим для этой функции
бинарную программу с другим порядком означиваний переменных, как на рис.2.
Видно, что доли путей ведущих в узлы, которым приписаны одинаковые функции для
первой программы и для второй (узлы 4
и 5 первой программы соответствуют узлам 3 и 4 второй)
отличаются.
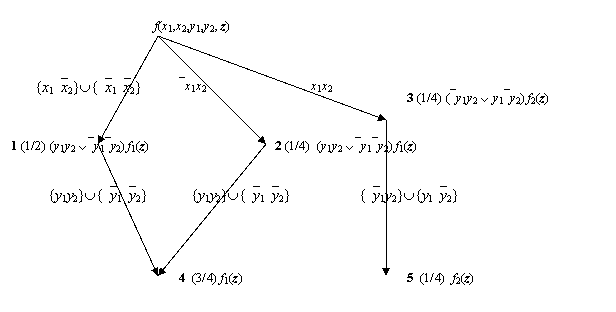
Рис. 1
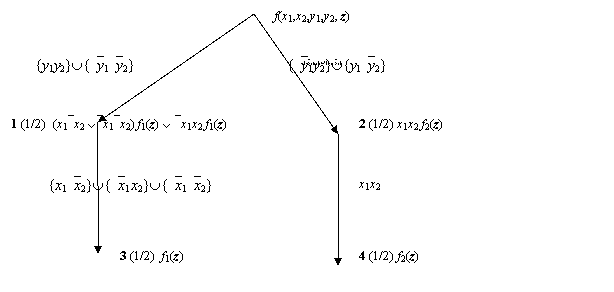
Рис. 2
Пример 2. Пусть
логическая функция f(x1, x2, y1, y2, z) =
(x1`x2Ú`x1`x2)(y1y2Ú`y1y2Ú`y1`y2)f1(z)Ú(`x1x2)(y1y2Úy1`y2)f1(z)Úx1x2`y1`y2f2(z).
Здесь z – это не пустой набор переменных
отличных от x1, x2, y1, y2. Начальный фрагмент бинарной программы для этой
функции приведен на рис.3.
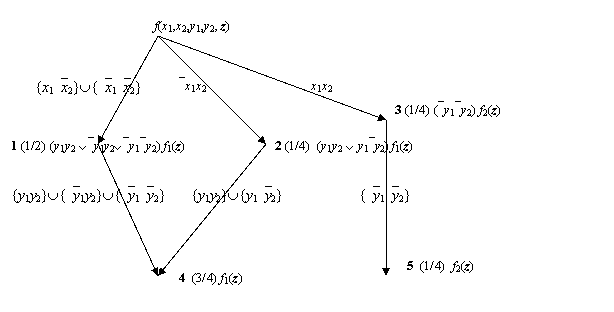
Рис. 3
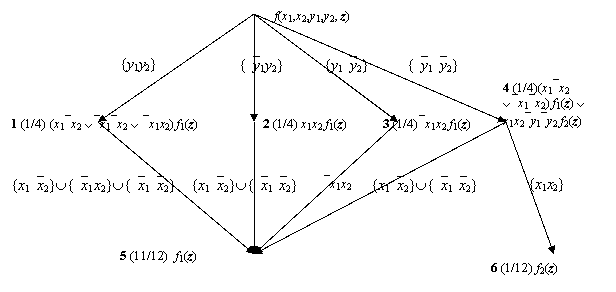
Рис. 4
Таким образом, если мы
хотим ввести меру неопределенности как функцию бинарной программы,
расположенной выше y-сечения, то необходимо учитывать
последовательности означиваний переменных в бинарной программе.
Введем ряд определений.
Пусть i-ый узел y-сечения соединен Nyz|y(j1|i), Nyz|y(j2|i), …, Nyz|y(jk|i) путями в точности с узлами соответственно j1, j2, …, jk yz-сечения и Nyz = Nyz|y(j1|i) + Nyz|y(j2|i) + …+ Nyz|y(jk|i) – это число всех путей, ведущих из i-го узла в yz-сечение. Тогда величина pyz|y(js|
i) = Nyz|y (js|
i)/Nyz – есть доля путей, ведущих из i-го узла y-сечения в js-ый узел yz-сечения, s = 1, 2, …, k среди всех путей из i-го узла y-сечения в yz-сечение. Понятно, что ås=1,k pyz|y(js|
i) = 1, так как j1, j2, …, jk – это все узлы yz-сечения, в которые имеются пути из i-го узла y-сечения.
Пусть в бинарной
программе i-ый узел y-сечения соединен путями в точности с
узлами j1, j2, …, jk yz-сечения; h1, h2, …, hm
– суть все узлы yzu-сечения, в которые мы попадаем из
узлов j1, j2, …, jk yz-сечения (см.рис.5). Тем самым из i-го узла y-сечения в узлы h1, h2, …, hm yzu-сечения мы можем попасть только
через какой-либо узел из j1, j2, …, jk yz-сечения.
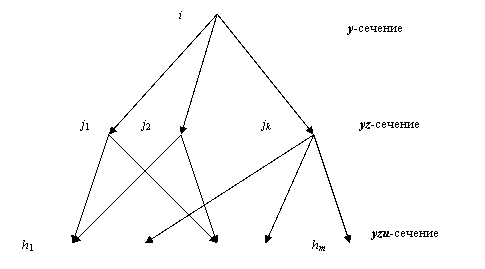
Рис.5
Из определения следует
равенство:
åt=1,k pyzu|yz(hs | jt)
pyz|y(jt | i) = pyzu|y(hs | i).
Действительно, i-ый узел y-сечения соединен путями с узлами j1, j2, …, jk yz-сечения и доля таких путей, ведущих
в jt–ый узел равна pyz|y(jt | i). В свою
очередь jt–ый узел соединен с некоторыми узлами
из совокупности h1, h2, …, hm yzu-сечения, причем доля таких путей,
ведущих из jt–го узла в hs-ый узел равна pyzu|yz(hs | jt).
Но тогда доля путей из i-го узла y-сечения в hs-ый узел yzu-сечения равна указанной сумме.
Справедливы следующие
равенства:
ås=1,m pyzu|y(hs | i) = 1; åt=1,k pyz|y(jt | i) = 1; ås=1,m pyzu|yz(hs | jt) = 1, t =
1, 2, …, k.
Последнее равенство выполняется
для тех пар узлов, которые соединены путями.
Теорема 1. Для всяких, не пересекающихся множеств y, z, u аргументов имеет место равенство å t=1,k, s=1,m pyzu|yz(hs|jt) pyz|y(jt|i) = 1.
Доказательство. По определению åt=1,k pyz|y(jt | i) = 1.
Для каждого из узлов j1, j2, …, jk yz-сечения имеем равенство ås=1,m pyzu|yz(hs | jt)
= 1, t = 1, 2, …, k.
Умножая каждый член
первой суммы на ås=1,m pyzu|yz(hs | jt),
получаем равенство ås=1,m åt=1,k pyzu|yz(hs | jt)
pyz|y(jt | i) = 1.
Теорема доказана.
Определим рекурсивно
величину pz(i) как долю
путей, проходящих из истока в i-ый узел z-сечения бинарной программы.
Пусть z = z1z2…zm – последовательность аргументов и
однородная бинарная программа имеет z1-сечение, z1z2-сечение, …, z1z2…zm-сечение,
причем множества путей заданы следующими значениями: Nz1z2…zm| z1z2…zm-1(i| jm-1), Nz1z2…zm-1| z1z2…zm-2(jm-1| jm-2), …, Nz1z2| z1 (j2| j1), Nz1(j1) при соответствующем именовании узлов сечений.
Нетрудно увидеть, что число Nz1z2…zm(i) всех путей
из истока программы в i-ый узел z-сечения равно сумме
åj1,j2,…,jm-1Nz1z2…zm|z1z2…zm-1(i|jm-1) Nz1z2…zm-1|z1z2…zm-2(jm-1|jm-2)…
… Nz1z2| z1(j2| j1) Nz1(j1),
где суммирование ведется по всем
узлам указанных сечений. Используя частичные суммы, получим, что эта сумма
равна
åjm-1 Nz1z2…zm| z1z2…zm-1(i| jm-1) Nz1z2…zm-1 (jm-1).
Здесь Nz1z2…zm-1 (jm-1) – это число путей, ведущих из
истока в jm-1-ый узел z1z2…zm-1-сечения.
Обозначим Nz общее число различных путей из
истока в z-сечение
и разделим каждый член последней суммы на величину Nz. Тогда отношение
Nz1z2…zm| z1z2…zm-1(i| jm-1) Nz1z2…zm-1(jm-1)/Nz
представляет собой долю всех путей из
истока в i-ый узел z-сечения, проходящих через jm-1-ый узел z1z2…zm-1-сечения
среди общего множества путей из истока в z-сечение.
Доля pz1z2…zm-1(jm-1) путей из
истока в z1z2…zm-сечение,
проходящих через узел jm-1 z1z2…zm-1-сечения также определяется общим числом
таких путей среди остальных, ведущих в z1z2…zm-сечение.
Причем только часть pz1z2…zm| z1z2…zm-1(i| jm-1) из них
ведет далее в i-ый узел z1z2…zm-сечение. Эти рассуждения позволяют
ввести такое индуктивное определение.
Базис конструкции. Если множество аргументов пусто, то pl(1) = 1. В этом случае узел l-сечения
- это исток бинарной программы.
Индуктивное построение. Пусть для некоторой последовательности z аргументов pz(j) есть доля
путей из истока в j-ый узел z-сечения, y – это новая
переменная и pzy|z(i | j) – доля
путей, ведущих из в j-го узла z-сечения в i-ый узел zy-сечения.
Тогда pzy(i) = åj pzy|z(i | j) pz(j).
Это определение распространяется
на произвольные множества аргументов y и z следующим образом.
pyz(i) = åj pyz|y(i | j) py(j).
Пусть z = z¢ u и мы уже получили, что pyz¢(h) = åj pyz¢ |y(h | j) py(j). По определению
pyz¢u(i) = åh=1,q pyz¢u |yz¢(i | h) pyz¢(h) = åh=1,q pyz¢u |yz¢(i | h) åj=1,k pyz¢ |y(h | j) py(j) =
åh=1,q,j=1,k pyz¢u |yz¢(i | h) pyz¢ |y(h | j) py(j).
Известно, что åh=1,q pyz¢u |yz¢(i | h) pyz¢ |y(h | j) = pyz¢u |y (i | j).
Следовательно,
pyz¢u(i) = åj=1,k pyz¢u
|y (i | j) py(j).
Справедливо утверждение.
Теорема 2. Справедливо равенство åi=1,h pz(i) = 1, где
суммирование ведется по всем узлам z-сечения.
Доказательство. Пусть pu(j) есть
известная доля путей из истока в узел j u-сечения, y – это
переменная, z = uy и åj=1,k pu ( j) = 1. По
определению, puy(i) = åj=1,k puy|u(i | j) pu(j), где puy|u(i | j) –
относительная доля путей, ведущих из j-го узла u-сечения в i-ый узел uy-сечения.
Следовательно, произведение puy|u(i | j) pu(j) есть доля
путей из истока в в i-ый узел uy-сечения, проходящих через j-ый узел u-сечения.
åi=1,h puy(i) = åi=1,h åj=1,k puy|u(i | j) pu(j) = åj=1,k(åi=1,h puy|u(i | j)) pu(j) = åj=1,k pu(j) = 1.
При доказательстве мы
использовали равенства åi=1,h puy|u(i | j) = 1 и åj=1,k pu(j) = 1.
Теорема доказана.
Назовем логической энтропией функции f, определяемой переменными y, величину
Hfy = -åi=1,k py(i) log py(i),
где суммирование ведется по всем
узлам y-сечения.
Из определения логической
энтропии следует, что в общем случае ее значение зависит от порядка означивания
переменных y в
бинарной программе. Это поясняют примеры 1 и 2. Опишем класс логических
функций, для которых логическая энтропия Hfy определяется лишь видом множества y переменных и не зависит от порядка
их означивания.
Справедливо следующее
утверждение.
Лемма 3. Пусть f(x, w) представляет всюду вычислимую функцию w = (x) и y  x. Тогда разложение этой функции по переменным y приводит к одному выражению с точностью до перестановки конъюнктивных и
дизъюнктивных членов. x. Тогда разложение этой функции по переменным y приводит к одному выражению с точностью до перестановки конъюнктивных и
дизъюнктивных членов.
Доказательство следует из
того, что при любом означивающем y-наборе sy в разложении присутствует
конъюнкция, первым членом которой является конъюнкт ysy и
вторым функция, которая получается из f(x, w) в результате этого означивания.
Теорема 4. Значение Hfy не зависит от порядка означиваний переменных y, а определяется только множеством y.
Из этого следует, что
логическая энтропия Hfy функции f(Y, w), представляющей физическую систему w = (Y), где - всюду определенная функция совпадает с ее
энтропией, определяемой переменными y, как она введена в [1].
Если же функция f(Y, w) представляет не всюду определенную вычислимую
функцию, то логическая энтропия зависит от порядка означивания переменных.
Если ясно, о какой
функции идет речь, то в обозначении Hfy будем опускать верхний индекс.
Понятие логической
энтропии введено, исходя из представления бинарной программы как некоторого
вычислителя. Тем самым она выступает мерой неопределенности процесса
вычисления. Ту же формулу можно получить в результате несколько иных
рассуждений. Как следствие получим, что логическая энтропия служит и мерой
сложности функции.
Определим по функции f(y, z) отношение y–эквивалентности y-наборов:
s1y » s2y Û f(s1y, z)
= f(s2y, z).
При этом говорим, что функция
f(s1y) определяется
тем классом эквивалентности, которому принадлежит y-набор s1y.
Пусть число всех классов y-эквивалентности равно k: s1, s2, …, sk; s11 Î s1, s21 Î s2, …, sk1 Î sk суть представители этих классов и 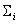 есть множество всех единичных означиваний
функции f(siy, z),
i = 1, 2, …, k. Назовем множество si ´ означиваний - порождаемым i-ым классом y-эквивалентности. Пусть есть множество всех единичных означиваний
функции f(siy, z),
i = 1, 2, …, k. Назовем множество si ´ означиваний - порождаемым i-ым классом y-эквивалентности. Пусть 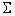 есть
множество всех единичных означиваний функции f(y, z). Тогда y–эквивалентность определяет разбиение
множества на k не пересекающихся подмножеств: = Èi=1,k si ´ , i = 1, 2, …, k – по числу классов эквивалентности. есть
множество всех единичных означиваний функции f(y, z). Тогда y–эквивалентность определяет разбиение
множества на k не пересекающихся подмножеств: = Èi=1,k si ´ , i = 1, 2, …, k – по числу классов эквивалентности.
Функции f(siy, z),
i = 1, 2, …, k, связаны с
исходной функцией f(y, z) очевидным образом:
f(y, z)
= Úi=1,k (ys1iÚ ys2iÚ …Ú ysmi) f(si1, z).
Здесь s1i, s2i, …, smi – означивания переменных у,
составляющие i-ый класс
эквивалентности, i = 1, 2, …, k, они определяют одну функцию f(si1, z), (обозначим её fi).
Представим функцию f(y, z) следующим образом:
f(y, z) = Úi=1,k [ysi] fi,
где [ysi] обозначает дизъюнкцию конъюнктов, определяемых всеми у–наборами
одного класса эквивалентности si = {s1i, s2i, …, smi}, i = 1, 2, …,
k.
Разлагая каждую функцию f(si1, z) по переменным z, получим равенство
f(y, z)
= Úi=1,k j=1,h [ysi] [zlj] f(s1i, l1j) = Úi=1,k j=1,h [ysi] [zlj] fij.
Сокращенно это разложение обозначим
так: f(y, z) =
Úi=1,k j=1,h [ysizlj] fij.
Множества s1, s2, …, sk попарно не пересекаются, но множества l1, l2, …, lh могут пересекаться.
Мы рассматриваем
логические функции, представляющие лишь всюду определенные вычислимые функции.
Поэтому каждая функция fij не равна тождественному нулю, i = 1, 2, …, k, j = 1,2, …, h. Несколько различных пар (i, j) индексов могут определять эквивалентные логические
функции fij. Перечислим все классы yz-эквивалентности. Пусть t-ый класс yz-эквивалентности характеризуется
множеством {(i, j1), (i, j2), …, (i, jq)}
пар индексов в разложении функции f(y, z). Тогда мы говорим, что t-ый класс yz-эквивалентности порожден i-ым классом y-эквивалентности.
Разложение функции f(y, z) по переменным y и z, можно представить ее в виде матрицы
Mf, как на рис.5.
|
z
у
|
l1
|
l2
|
l3
|
…
|
|
s1
|
f11
|
f12
|
f13
|
…
|
|
s2
|
f21
|
f22
|
f23
|
…
|
|
s3
|
f31
|
f32
|
f33
|
…
|
|
…
|
…
|
…
|
…
|
…
|
Рис. 5
Здесь fij обозначает функцию f(s1i, l1j), i-ая строка
соответствует i-му классу y-эквивалентности, i=1, 2, …, k, j-ый столбец - j-му классу z-эквивалентности, j=1, 2, …, h. В общем
случае нескольким парам (i, j), где i – номер столбца и j – номер
строки, может соответствовать один класс эквивалентности yz-наборов. Но число классов yz-эквивалентности не больше числа
таких различных пар. Все порожденные одним i–м y-классом yz-классы характеризуются эквивалентными
функциями из одной i–ой строки.
Введем теперь показатель,
аналогичный тому, который использовался при исследовании бинарных программ.
Определим pyz|y(j|i) как условную долю j-го yz-класса, порожденного i-м y-классом среди всех yz-классов, порожденных i-м y-классом. Из разложения функции f по переменным и определения бинарной программы понятно,
что все введенные ранее равенства относительно условных и абсолютных долей
сохраняются при новой интерпретации. В частности, определение абсолютной доли py(i) i-го y-класса среди остальных y-классов выглядит так.
Базис конструкции. При пустом множестве аргументов имеется единственный класс
эквивалентности, который определяется самой функцией f и поэтому доля его pl(1) = 1.
Индуктивное построение. Пусть для некоторой последовательности z аргументов pz(j) есть доля j-го класса z-эквивалентности среди остальных z-классов, y – это новая
переменная и pzy|z(i | j) – доля i-го zy-класса
среди всех zy-классов, порожденных j-м z-классом. Тогда pzy(i) = åj pzy|z(i | j) pz(j).
Рассмотрим однородную
бинарную программу pf для функции f(y). Пусть N1, N2, …, Nk
– суть все узлы y-сечения и Т1, Т2,
…, Тk – совокупности путей, проходящих из истока программы в узлы
соответственно N1, N2, …, Nk, причем мощности множеств Т1, Т2, …, Тk равны соответственно t1, t2, …, tk и t = åi=1,k ti. Каждый узел Ni соответствует, с одной стороны, в
точности одному классу у-эквивалентности,
а с другой, - единственной логической функции, определяемой всяким у-набором
из этого класса у-эквивалентности. По определению, доля py(i) всех
наборов, определяемых одним классом у-эквивалентности,
соответствующего узлу Ni, совпадает с долей py(i) путей из истока
в i-ый узел y-сечения. i = 1, 2, …, k.
При таком определении
абсолютной доли, выполняется теорема, аналогичная Теореме 1.
Теорема 5. Имеет место равенство åi pz(i) = 1.
Если мы рассматриваем
логические функции, представляющие всюду определенные вычислимые функции, то
верно следующее утверждение.
Лемма 6. Пусть py(i) есть доля i-го класса y-эквивалентности, qz(j) – доля j-го класса z-эквивалентности. Тогда доля yz-наборов,
которые характеризуются принадлежностью
y-наборов i-му классу
y-эквивалентности и z-наборов
j-му
классу z-эквивалентности
среди всех yz-наборов
равна произведению рy(i)qz(j), i = 1, 2,…, k, j = 1, 2, …, h.
Доказательство. Все логические функции fij, i=1, 2, …, k, j=1, 2, …. h не являются тождественно нулевыми. Следовательно, для
каждого y-набора sri Î si и для каждого z-набора lqj Î lj все конъюнкты вида ysrizlqj входят в разложение исходной функции.
Лемма доказана.
С другой стороны, если
рассматривать логические функции, представляющие не всюду определенные функции,
то утверждение места не имеет. Действительно, в этом случае некоторые функции
матрицы Mf могут быть тождественно нулевыми и,
следовательно, для y-набора sri Î si для некоторых z-наборов lqj Î lj конъюнкты вида ysrizlqj могут не входить в разложение
исходной функции. Следовательно, не все yz-наборы, у которых y-наборы из класса si, характеризуются принадлежностью z-наборов какому-либо классу z-эквивалентности.
Сложность зависимости
функции f(y) от переменных y характеризуется фактор-множеством у-эквивалентности. Действительно, чем
больше фактор-множество, тем больше различных подформул встречается в разложении
логической функции по этим переменным. В терминах бинарной программы мощности
фактор-множества у–эквивалентности соответствует число узлов у–сечения.
Если py(i) есть доля
путей, проходящих из истока в i-ый узел y-сечения, то
обратная величина ty(i) = 1/
py(i) пропорциональна
числу путей, ведущих из истока в этот узел, i = 1,2, …, k. åi=1,k py(i) log ty(i) есть математическое ожидание случайной
величины log ty(i), i = 1,2, …, k, с распределением
py(i).
Введем следующее
определение.
Эффективной пропускной способностью одного узла у–сечения бинарной программы
назовем величину t, такую, что log t = åi=1,k py(i) log ty(i). Таким
образом, эффективную пропускную способность можно представлять как
математическое ожидание величины, пропорциональной числу путей, проходящих через
один узел y-сечения.
Поэтому эффективная пропускная способность отличается от «реальной» некоторой
аддитивной константой. Если доли py(i) одинаковы,
то log t = log`t . В этом случае эффективная пропускная способность
совпадает с числом путей из истока, которые проходят через один узел y-сечения.
Введем величину t = åi=1,k ty(i) которая пропорциональна общему числу
путей, ведущих из истока в y-сечение. Величину Нy = log (t/t) назовем эффективным у–сечением. Тем самым эффективное у–сечение есть мера
сложности бинарной программы, расположенной выше у–сечения: при большем
эффективном сечении Нy и при постоянном числе всех путей из
истока в у–сечение, среднее число путей, проходящих через один узел сечения,
мало, а число узлов в сечении - велико. Но чем шире у–сечение, тем сложнее
зависимость логической функции от переменных у, так как число
различных подформул, участвующих в разложении функции по переменным у больше. Поэтому зависимости исходной функции
от переменных у выражается сложнее.
Нy =
log (t/t)
= log t – log t = log t –
åi=1,k py(i)
log ty(i)
= -åi=1,k (ty(i)/t) log (ty(i)/t) = -åi=1,k py(i)
log py(i).
Как видно, величина
эффективного y-сечения
и энтропии логической функции совпадают. Заметим, что энтропия получена из
определения неопределенности выходных значений от входных, а эффективное сечение
получено из анализа сложности зависимости функции от ее аргументов.
2. Некоторые интерпретации логической энтропии. Поясним с содержательной точки зрения
понятие логической энтропии.
Пусть f(y, z) есть логическая функция и x(у)
есть функция, значение которой от аргументов sу равно номеру того класса у-эквивалентности, которому
принадлежит кортеж sу. Обозначим долю таких y-наборов, при которых значение
функции x(у) равно i, i = 1, 2, …, k, среди всех наборов через pi.
Будем говорить, что переменные у имеют распределение pу(1), pу(2), …, pу(k). Понятно,
что Si=1,k pу(i) = 1.
Назовем функцию, которая получается из f(y, z) подстановкой y–наборов из i-го класса эквивалентности - соответствующей значению pi. Следовательно, показатель неожиданности
-log2 pi функции x(у) зависит от доли наборов,
определяемых i-м классом у-эквивалентности. Чем
больше наборов в i-м классе, тем меньше неожиданность
того, что конкретное означивание ему принадлежит. В терминах бинарной программы
это выглядит так: чем больше путей определяется одним классом у–эквивалентности,
тем большая доля вычислений осуществляется промежуточным вычислителем, который
соответствует данному классу и ассоциируется с соответствующим узлом у-сечения
программы. Логическая энтропия, определяемая переменными у, есть усредненная
неожиданность того, что конкретное вычисление будет реализовываться промежуточным
вычислителем, соответствующим конкретному классу у-эквивалентности (в терминах
бинарной программы – некоторому узлу y-сечения).
В
теории информации энтропия служит мерой свободы
системы: чем больше у системы степеней свободы, т.е. чем меньше на нее наложено
ограничений, тем больше ее энтропия. Поэтому энтропия максимальна при одинаковой
доле наблюдаемых событий, а всякое отклонение от него приводит к ее уменьшению.
В пределе, когда доля одного события равна 1, энтропия равна нулю.
Применительно к логической энтропии, под степенями свободы понимается число
классов у-эквивалентности. Чем их меньше, тем больше определенность,
какой промежуточный вычислитель используется для продолжения вычисление. И
наоборот, чем больше классов эквивалентности и чем однороднее доли p1, p2, …, pk, тем больше
возможностей для выбора того или иного промежуточного вычислителя и, следовательно,
больше неопределенность.
В терминах сложности
логической функции эти рассуждения выглядят так: если переменные y определяют небольшое
фактор-множество, то они описывают лишь небольшое число различных свойств
логической функции. Очевидно, что для описания небольшого числа свойств требуется
меньше параметров (в нашем случае - аргументов) и наоборот, чем разнообразнее
проявления системы, тем больше параметров необходимо для ее описания. При
прочих равных условиях, более сложная система наблюдателю кажется менее определенной
и наоборот, чем больше определенности у наблюдателя, тем проще зависимость
демонстрируемого поведения системы от входных параметров. В данном контексте
под сложностью зависимости системы от аргументов y понимается число классов у-эквивалентности.
Это согласуется с определением неопределенности функции от переменных у,
как сложности зависимости от этих аргументов. Чем меньше классов у-эквивалентности,
тем, с одной стороны, меньше средний показатель неожиданности, а с другой, -
тем проще выражается зависимость функции от этих аргументов. Если же классов
эквивалентности много, то больше средний показатель неожиданности и функция
сложнее зависит от аргументов у. Тем самым, чем больше энтропия Нy, тем сложнее выражается зависимость
функции от аргументов у и наоборот.
Приведем теперь
интерпретацию логической энтропии с позиций статистической модели
равновероятных последовательностей. Для этого представим логическую функцию f(y, z) таблицей истинности, в которой
приведены лишь ее единичные означивания. Разложение по y выглядит следующим образом:
f(y, z)
= Úi=1,k [ysi] f(si1, z).
Полагаем, что все
переменные y
случайны и независимы, и py(i), i = 1, 2, …, k, есть доля наборов, включающих y-поднаборы из i-го класса y-эквивалентности в достаточно большом
случайно порожденном множестве единичных означиваний, мощность которого равна N. Тогда число наборов, обладающих y–поднаборами из i-го класса y-эквивалентности, равно Ni = N py(i).
По закону больших чисел
во всяком достаточно большом подмножестве единичных означиваний доля
означиваний, порожденных i-м классом y-эквивалентности совпадает с py(i), i = 1, 2, …, k и доли наборов, порожденных каждым
из k классов
y-эквивалентности,
не зависят от вида множества единичных означиваний. Поэтому из N наборов Ni = N py(i) порождены i-м классом и
вероятность выбора такого множества единичных означиваний, которая
характеризуется распределением py(i), i = 1, 2, …, k, по классам y-эквивалентности, равна q = py(1)N1py(2)N2
… py(k)Nk = (py(1)py(1)py(2)py(2) … py(k)
py(k))N. Неопределенность H* всего множества единичных означиваний равна - log q. Поэтому H* = -N åi=1,k py(i) log py(i). Но тогда
-åi=1,k py(i) log py(i) = H*/N представляет собой среднюю неопределенность,
которая приходится на единственное единичное означивание.
Тем самым, получили еще
одну интерпретацию логической энтропии:
формула -åi=1,k py(i) log py(i) определяет
среднюю неопределенность, которая приходится на одно единичное означивание
функции f(y, z), если
их классификация осуществляется с помощью y-эквивалентности
при достаточно большом числе независимо порожденных единичных означиваний.
Наконец, еще одна
трактовка логической энтропии основывается на следующих рассуждениях.
Пусть y-эквивалентность порождает k классов. Присвоим каждому из N единичных означиваний функции f(y, z) номер того класса из {1, 2, …, k}, порождением которого он является. Число различных
перестановок N единичных означиваний из которых Ni = N pi обладают номером i, равно
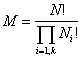 . .
Тогда энтропия этого случайного
множества
H* = log M = log N! - åi=1,k log Ni!.
По формуле Стирлинга
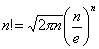 . .
Полагая, что N достаточно велико, имеем
H* = N log N - åi=1,k Ni log Ni = åi=1,k Ni log N - åi=1,k Ni log Ni = - N åi=1,k py(i) log py(i).
В этом случае энтропия
- åi=1,k py(i) log py(i) = (1/N) log M
есть средняя неопределенность,
которая приходится на одно единичное означивание при их случайном порождении.
Последние интерпретации
логической энтропии проясняют ее поведенческую природу. Под N понимается число проводящих путей бинарной программы
из истока в сток. Тогда Ni есть число таких путей, проходящих
через i-ый узел y-сечения, pi – доля этих путей. M есть число способов распределения вычислений по k промежуточным вычислителям, соответствующих узлам y-сечения, при условии, что на i-ый вычислитель приходится pi-ая
доля всех вычислений. Но тогда log M / N есть средняя неопределенность того,
на каком вычислителе будет обрабатываться отдельная последовательность аргументов.
Если k = 1, то неопределенность равна 0. Если k возрастает, то возрастает и величина max(-åi=1,k py(i) log py(i)). То есть
неопределенность отнесения того или иного единичного означивания к
соответствующему классу растет.
Из последнего определения
следует, что логическая энтропия представляет собой информацию, которую мы
получаем об одном единичном означивании, при известном разложении функции по
переменным y. Единичные
означивания, порожденные одним классом y-эквивалентности на промежуточном
этапе разложения по y не различимы с точностью до y- эквивалентности. Они
характеризуются одним номером класса. Следовательно, информация, которая
приходится на одно означивание при известном разложении по переменным y касается именно принадлежности к
классу эквивалентности.
Достаточно очевидна
аналогия такого представления с представлением энтропии в Теории информации как
меры информации, которая передается одним символом сообщения,. В нашем случае
каждое единичное означивание является носителем сигнала, который указывает на
принадлежность соответствующего y-набора конкретному классу эквивалентности.
Пример 3. Опишем два
класса логических функций. Первый называется локальным и характеризуется
энтропией, не зависящей от переменных y, определяющих сечение бинарной
программы. Второй обладает энтропией, линейно зависящей от мощности множества y переменных не зависимо от порядка их
означивания.
Первый класс функций
описан в [2]. Для них доказана ограниченность сечения бинарных программ при
некотором порядке означивания переменных. Содержательно это значит, что между
переменными функций из этого класса имеется большое число зависимостей или, что
эквивалентно, такие функции обладают небольшим числом подфункций.
С другой стороны в [2]
описан класс не локальных функций, для бинарных программ которых любое y-сечение (когда число переменных y не превосходит половины от числа
всех аргументов) содержит не менее 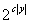 узлов, где c – положительная константа. При этом доли путей,
ведущих в разные узлы y-сечения, совпадают. Отсюда следует,
что логическая энтропия, определяемая такими множествами аргументов, пропорциональна
| y |. Содержательно это обозначает, что
для таких функций, их аргументы по большей части попарно независимы или, что
эквивалентно, они обладают большим числом подфункций. узлов, где c – положительная константа. При этом доли путей,
ведущих в разные узлы y-сечения, совпадают. Отсюда следует,
что логическая энтропия, определяемая такими множествами аргументов, пропорциональна
| y |. Содержательно это обозначает, что
для таких функций, их аргументы по большей части попарно независимы или, что
эквивалентно, они обладают большим числом подфункций.
Если говорить о том,
какова логическая энтропия большинства логических функций, то отметим, что для
почти всех логических функций сложность реализации контактными схемами
ограничена снизу экспонентой от числа переменных. Следовательно, почти все
логические функции при любом построении бинарных программ обладают максимальной
энтропией, сравнимой с общим числом их переменных.
Литература
1.
Брошкова
Н.Л., Попов С.В., О проектировании информационных систем. Препринт ИПМ РАН им.
М.В.Келдыша, 2005.
2.
Брошкова
Н.Л., Попов С.В., О локальности информационных систем. Препринт ИПМ РАН им.
М.В. Келдыша, 2005.
3.
Шеннон
К. Работы по теории информации и кибернетике, М.: ИЛ. 1963, - 830 с.
4.
Колмогоров
А.Н. Теория информации и теория алгоритмов, М.: Наука, 1987, - 303 с.
5. Файнстейн А. Основы теории
информации. М.: ИЛ, 1960. – 140 с.
|