Развитие метода полиномиальной регрессии и его практическое применение в задачах распознавания
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
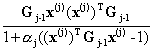

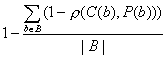
|
W |
NE(W) |
N(W) |
vE(W) |
v(W) |
|
1 |
0 |
0 |
0 |
0 |
|
2 |
0 |
0 |
0 |
0 |
|
3 |
0 |
0 |
0 |
0 |
|
4 |
0 |
0 |
0 |
0 |
|
5 |
5 |
6 |
0,8333 |
0,0006 |
|
6 |
10 |
27 |
0,3704 |
0,0028 |
|
7 |
26 |
67 |
0,3881 |
0,0068 |
|
8 |
31 |
124 |
0,25 |
0,0127 |
|
9 |
34 |
206 |
0,165 |
0,021 |
|
10 |
25 |
293 |
0,0853 |
0,0299 |
|
11 |
10 |
508 |
0,0197 |
0,0519 |
|
12 |
6 |
945 |
0,0063 |
0,0969 |
|
13 |
4 |
1388 |
0,0029 |
0,1418 |
|
14 |
0 |
1815 |
0 |
0,1855 |
|
15 |
1 |
1639 |
0,0006 |
0,1675 |
|
16 |
0 |
2769 |
0 |
0,2829 |
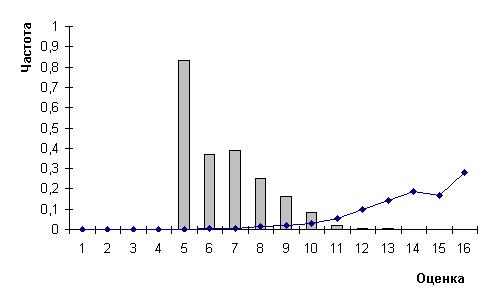
Рис.2.
Распределения частот ошибок (гистограмма) и оценок (график) для
прямых печатных букв и цифр на длинном векторе
Для короткого вектора х1 точность составила
0,9681, а быстродействие - 2650 символов/сек.
Распределения оценок и ошибок представлены в таблице 2 и на рисунке 3.
Таблица
2. Распределения оценок и ошибок распознавания прямых печатных
букв и цифр на коротком векторе
|
W |
NE(W) |
N(W) |
vE(W) |
v(W) |
|
1 |
0 |
0 |
0 |
0 |
|
2 |
0 |
0 |
0 |
0 |
|
3 |
0 |
0 |
0 |
0 |
|
4 |
2 |
3 |
0,6667 |
0,0003 |
|
5 |
14 |
26 |
0,5385 |
0,0027 |
|
6 |
34 |
90 |
0,3778 |
0,0092 |
|
7 |
37 |
173 |
0,2707 |
0,0177 |
|
8 |
45 |
283 |
0,159 |
0,0289 |
|
9 |
47 |
515 |
0,0913 |
0,0526 |
|
10 |
57 |
905 |
0,063 |
0,0925 |
|
11 |
39 |
1175 |
0,0332 |
0,12 |
|
12 |
17 |
1483 |
0,0115 |
0,1515 |
|
13 |
15 |
1575 |
0,0095 |
0,1609 |
|
14 |
3 |
1177 |
0,0025 |
0,1202 |
|
15 |
1 |
991 |
0,001 |
0,1013 |
|
16 |
0 |
1391 |
0 |
0,1421 |
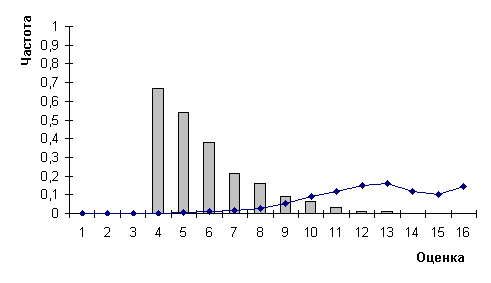
Рис.3.
Распределения частот ошибок (гистограмма) и оценок (график) для
прямых печатных букв и цифр на коротком векторе
Обратим внимание на две особенности полученных статистик обоих типов векторов:
-
ошибки
с максимальной оценкой 16 отсутствуют,
доля этой оценки по отношению к общему числу распознанных образов составляет
около 0,14;
-
частота
ошибок со старшими оценками (то есть равными 14, 15 и 16) составляет 0,0002,
доля этих оценок составляет около 0,63.
То есть на тестовых базах метод порождает оценки, отвечающие
критериям монотонности. Некоторое нарушение монотонности в области низких
оценок не представляется важным.
Использование короткого вектора позволяет повысить быстродействие примерно в 2
раза, при этом почти в 2 раза увеличивается количество ошибок распознавания.
Печатные прямые и курсивные цифры.
Обучение проводилось на базе в 95 тыс.
элементов с коротким вектором х1. При обучении и распознавании между
прямыми и курсивными символами не делалось различий. Точность на обучающей
последовательности составляет 0,9946 при однократном обучении, а после третьего
прохода по базе – 0,9966.
Тестовая последовательность содержала 129822 образов.
Полученная точность равняется 0,9812,
а быстродействие - 11500 символов/сек.
Распределения оценок и ошибок представлены в таблице 3 и на рисунке 4.
Таблица
3. Распределения оценок и ошибок распознавания прямых и
курсивных печатных цифр
|
W |
NE(W) |
N(W) |
vE(W) |
v(W) |
|
1 |
0 |
0 |
0 |
0 |
|
2 |
0 |
0 |
0 |
0 |
|
3 |
0 |
0 |
0 |
0 |
|
4 |
6 |
9 |
0,6667 |
0,0001 |
|
5 |
76 |
142 |
0,5352 |
0,0011 |
|
6 |
301 |
515 |
0,5845 |
0,004 |
|
7 |
577 |
1417 |
0,4072 |
0,0109 |
|
8 |
480 |
2319 |
0,207 |
0,0179 |
|
9 |
357 |
3447 |
0,0603 |
0,0266 |
|
10 |
260 |
4312 |
0,029 |
0,0332 |
|
11 |
173 |
5959 |
0,0118 |
0,0459 |
|
12 |
106 |
8968 |
0,0017 |
0,0691 |
|
13 |
22 |
12931 |
0,0006 |
0,0996 |
|
14 |
11 |
19200 |
0 |
0,1479 |
|
15 |
0 |
23357 |
0 |
0,1799 |
|
16 |
0 |
47246 |
0 |
0,3639 |
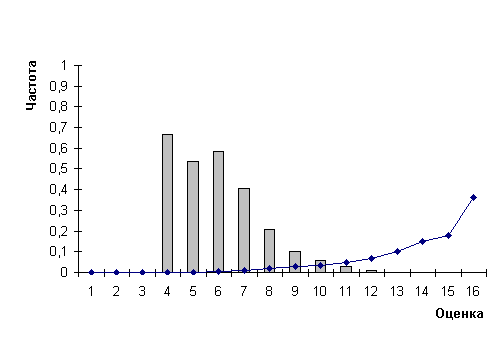
Рис.4.
Распределения частот ошибок (гистограмма) и оценок (график) для
прямых и курсивных печатных цифр
Для этого класса образов отметим, что распознавание полиномами дало сходную точность по отношению к распознаванию прямых печатных букв и цифр и очень высокое быстродействие. Обратим внимание, что алфавит обучения и распознавания содержал 20 символов (10 прямых и 10 курсивных цифр). Отметим, что частота ошибок со старшими оценками составляет 0,0001, доля этих оценок составляет около 0,69.
Рукопечатные цифры. После обучения по
базе в 175 тыс. элементов для длинного вектора х полученная матрица на той
же базе обеспечивает распознавание 98.33% элементов, а после четвертой итерации
качество распознавания возрастает до 98.81%. Также производилось обучение на
коротком векторе х1 (12).
Тестовая последовательность содержала 8416 образов.
Для длинного вектора х полученная точность равняется 0,9846,
а быстродействие - 4000 символов/сек.
Распределения оценок и ошибок представлены в таблице 4 и на рисунке 5.
Таблица
4. Распределения оценок и ошибок распознавания рукопечатных
цифр с помощью длинного вектора
|
W |
NE(W) |
N(W) |
vE(W) |
v(W) |
|
1 |
0 |
0 |
0 |
0 |
|
2 |
0 |
0 |
0 |
0 |
|
3 |
0 |
0 |
0 |
0 |
|
4 |
5 |
6 |
0,8333 |
0,0007 |
|
5 |
10 |
19 |
0,5263 |
0,0023 |
|
6 |
17 |
51 |
0,3333 |
0,0061 |
|
7 |
32 |
105 |
0,3048 |
0,0125 |
|
8 |
19 |
162 |
0,1173 |
0,0192 |
|
9 |
22 |
230 |
0,0957 |
0,0273 |
|
10 |
14 |
370 |
0,0374 |
0,044 |
|
11 |
5 |
509 |
0,0092 |
0,0605 |
|
12 |
5 |
645 |
0,0078 |
0,0766 |
|
13 |
0 |
951 |
0 |
0,113 |
|
14 |
0 |
1195 |
0 |
0,142 |
|
15 |
1 |
1293 |
0,0008 |
0,1536 |
|
16 |
0 |
2875 |
0 |
0,3416 |
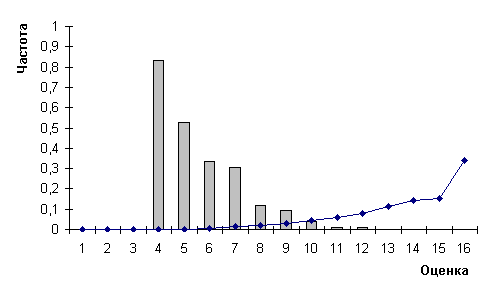
Рис.5.
Распределения частот ошибок (гистограмма) и оценок (график) для
распознавания рукопечатных цифр с помощью длинного вектора
Для короткого вектора х1
полученная точность равняется 0,9703, а быстродействие
- 9500 символов/сек. Распределения
оценок и ошибок представлены в таблице 5 и на
рисунке 6.
Таблица
5. Распределения оценок и ошибок распознавания рукопечатных
цифр с помощью короткого вектора
|
W |
NE(W) |
N(W) |
vE(W) |
v(W) |
|
1 |
0 |
0 |
0 |
0 |
|
2 |
0 |
0 |
0 |
0 |
|
3 |
0 |
0 |
0 |
0 |
|
4 |
5 |
11 |
0,4545 |
0,0013 |
|
5 |
19 |
51 |
0,3725 |
0,0061 |
|
6 |
40 |
97 |
0,4124 |
0,0115 |
|
7 |
55 |
218 |
0,2523 |
0,0259 |
|
8 |
56 |
302 |
0,1854 |
0,0359 |
|
9 |
25 |
427 |
0,0585 |
0,0507 |
|
10 |
28 |
566 |
0,0495 |
0,0673 |
|
11 |
12 |
695 |
0,0173 |
0,0826 |
|
12 |
9 |
902 |
0,01 |
0,1072 |
|
13 |
1 |
1096 |
0,0009 |
0,1302 |
|
14 |
2 |
1096 |
0,0018 |
0,1302 |
|
15 |
0 |
1044 |
0 |
0,124 |
|
16 |
0 |
1911 |
0 |
0,227 |
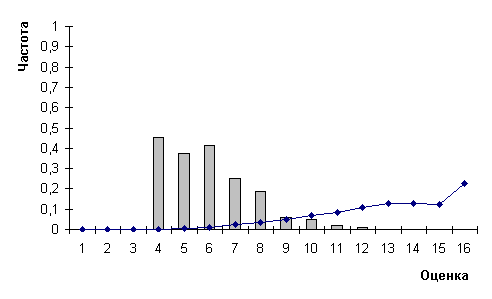
Рис.6.
Распределения частот ошибок (гистограмма) и оценок (график) для
распознавания рукопечатных цифр с помощью короткого вектора
Распознавание методом полиномов (с длинным и коротким векторами) класса образов рукопечатных цифр дало сходные характеристики точности и быстродействия по отношению к распознаванию прямых печатных букв и цифр. Кривые распределений, характеризующие монотонность, также аналогичны кривым для прямых печатных букв и цифр (см. рис. 2,3).
На основании приведенных результатов численных экспериментов можно сделать вывод о том, что реализация метода полиномов показала высокие характеристики точности, быстродействия и, в особенности, монотонности оценок.
4. Обсуждение результатов
В заключении попробуем ответить на вопрос: зачем нужен еще один метод распознавания символов, в то время как их описано немалое множество?
Обратимся к схеме алгоритмов в
программах распознавания текстов (OCR) [10] и в системах массового ввода
структурированных документов [11], включающей в себя:
-
алгоритмы
бинаризации;
-
предварительное
распознавание текста;
-
сегментацию
страницы на блоки с текстом, таблицами, иллюстрациями, поля с рукопечатным текстом,
разделительные линии и т.п. объекты;
-
распознавание
строк (полей) символов с неизвестными границами;
-
адаптацию
к особенностям страницы и использованным шрифтам для многопроходного распознавания;
-
словарную
коррекцию и дораспознавание;
-
финальную
сегментацию (форматирование в известные форматы).
Перечисленные этапы могут повторяться в соответствии с
логикой адаптивного распознавания страницы документа. Любой из этих этапов
может использовать методы распознавания символов для решения следующих задач:
-
классификация
(отнесение к одному из известных символов) образа;
-
отделение
символов от «несимволов» - образов, не входящих в алфавит распознавания;
-
оценка
принадлежности образа к одному из известных классов.
Легко видеть, что основной характеристикой для двух последних задач служит монотонность оценок, а не точность распознавания. Учитывая повторяемость этапов распознавания и сложность переборных алгоритмов сегментации, следует обращать внимание на быстродействие методов распознавания символов. Ответ на вопрос о необходимости создания новых методов распознавания таков: новые методы представляют интерес с точки зрения характеристик качества, превосходящих свойства известных методов.
Сопоставим характеристики метода полиномов и двух известных методов:
-
нейронные
сети, описанные в [12] и обладающие высочайшей характеристикой точности;
-
метод
сравнения с эталоном [13,14], обладающий высочайшим быстродействием (как
обучения, так и распознавания) и высокой монотонностью оценок.
В качестве тестовой последовательности возьмем базу графических образов, содержащую 8416 рукопечатных цифр. Особенности процессов обучения методов сравнения с эталонами и нейронной сети рассматривать не будем.
Таблица
6. Распределения оценок и ошибок распознавания методом
сравнения с эталонами 3х5
|
W |
NE(W) |
N(W) |
vE(W) |
v(W) |
|
1 |
0 |
1 |
0 |
0,0001 |
|
2 |
0 |
0 |
0 |
0 |
|
3 |
1 |
2 |
0,5 |
0,0002 |
|
4 |
7 |
10 |
0,7 |
0,0012 |
|
5 |
5 |
8 |
0,625 |
0,001 |
|
6 |
10 |
22 |
0,4545 |
0,0026 |
|
7 |
12 |
49 |
0,2449 |
0,0058 |
|
8 |
15 |
70 |
0,2143 |
0,0083 |
|
9 |
27 |
95 |
0,2842 |
0,0113 |
|
10 |
37 |
233 |
0,1588 |
0,0277 |
|
11 |
65 |
452 |
0,1438 |
0,0537 |
|
12 |
87 |
932 |
0,0933 |
0,1107 |
|
13 |
124 |
2074 |
0,0598 |
0,2464 |
|
14 |
127 |
2414 |
0,0526 |
0,2868 |
|
15 |
99 |
1791 |
0,0552 |
0,2128 |
|
16 |
8 |
255 |
0,0314 |
0,0303 |
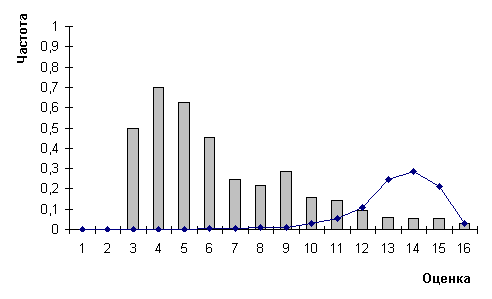
Рис.7.
Распределения частот ошибок (гистограмма) и оценок (график) для распознавания методом сравнения с
эталонами 3х5
Для метода сравнения с эталонами размера 3х5 [12] полученная точность равняется 0,9259, а быстродействие - 8000 символов/сек. Распределения оценок и ошибок представлены в таблице 6 и на рисунке 7.
Таблица 7. Распределения оценок и ошибок распознавания нейронной сетью
|
W |
NE(W) |
N(W) |
vE(W) |
v(W) |
|
1 |
4 |
11 |
0,36 |
0,0013 |
|
2 |
2 |
4 |
0,5 |
0,0004 |
|
3 |
2 |
4 |
0,5 |
0,0004 |
|
4 |
1 |
4 |
0,25 |
0,0004 |
|
5 |
0 |
2 |
0 |
0,0002 |
|
6 |
1 |
4 |
0,25 |
0,0004 |
|
7 |
0 |
4 |
0 |
0,0004 |
|
8 |
4 |
9 |
0,44 |
0,001 |
|
9 |
0 |
8 |
0 |
0,0009 |
|
10 |
0 |
12 |
0 |
0,0014 |
|
11 |
0 |
20 |
0 |
0,0024 |
|
12 |
2 |
23 |
0,087 |
0,0027 |
|
13 |
0 |
20 |
0 |
0,0024 |
|
14 |
2 |
58 |
0,034 |
0,0069 |
|
15 |
1 |
97 |
0,01 |
0,0115 |
|
16 |
1 |
8136 |
0,0001 |
0,9667 |
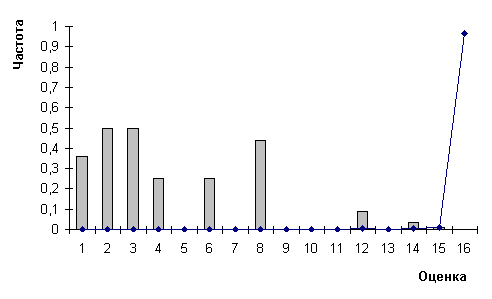
Рис.8.
Распределения частот ошибок (гистограмма) и оценок (график) для распознавания нейронной сетью
Для нейронной сети размера 16х16 [12] полученная точность равняется 0,9976, а быстродействие - 4500 символов/сек. Распределения оценок и ошибок представлены в таблице 7 и на рисунке 8.
Вначале сопоставим характеристики нейронной сети и полиномов. Мы видим неоспоримое превосходство нейронной сети над полиномами в точности распознавания (0,9976 против 0,9846) и в распределении оценок (нейронная сеть порождает 95,79% случаев распознаваний с максимальной оценкой 16, полиномы же – всего 22,7%). В то же время количество ошибок с максимальной оценкой 16 для нейронной сети составляет 1 случай, а для полиномов 0. И это не является случайностью, поскольку во всех приведенных выше результатах для полиномов ошибки с максимальной оценкой отсутствуют. Быстродействие методов сходно.
Метод сравнения с эталонами находится вне конкуренции с полиномами (также как и с указанной нейронной сетью) из-за возможности быстрого дообучения, не превосходящего нескольких секунд. При этом оценки метода сравнения с эталонами также монотонны, что можно видеть в таблице 6 и на рис. 7. Однако, на графике рис. 7 заметно сильное уменьшение доли старших оценок (0,0303 против 0,227 у полиномов для максимальной оценки). Ухудшение монотонности оценок по отношению к монотонности оценок метода полиномов очевидно также в численном выражении частот ошибок для старших оценок (для сравнения см. таблицы 6 и 4).
Сравнительные результаты распознавания рукопечатных цифр сведены в таблицу 8, которая содержит характеристики качества и распределения для старших оценок для трех методов: полиномов с коротким вектором, нейронной сети и сравнения с эталонами.
Таблица 8. Сводные характеристики методов полиномов, нейронной сети
и сравнения с эталонами.
|
|
|
Старшие оценки |
|||||||
|
Метод |
Характеристика |
13 |
14 |
15 |
16 |
||||
|
Полиномы |
Точность |
0,9846 |
|||||||
|
Быстродействие |
4000 образов/сек |
||||||||
|
NE(W) vE(W) |
0 0 |
0 0 |
1 0,0008 |
0 0 |
|||||
|
N(W) v(W) |
951 0,113 |
1195 0,142 |
1293 0,1536 |
2875 0,3416 |
|||||
|
Сравнение с эталоном |
Точность |
0,9259 |
|||||||
|
Быстродействие |
8000 символов/сек |
||||||||
|
NE(W) vE(W) |
124 0,0598 |
127 0,0526 |
99 0,0552 |
8 0,0314 |
|||||
|
N(W) v(W) |
2074 0,2464 |
2414 0,2868 |
1791 0,2128 |
255 0,0303 |
|||||
|
Нейронная сеть |
Точность |
0,9976 |
|||||||
|
Быстродействие |
4500 образов/сек |
||||||||
|
NE(W) vE(W) |
0 0,0 |
2 0,034 |
1 0,01 |
1 0,0001 |
|||||
|
N(W) v(W) |
20 0,0024 |
58 0,0069 |
97 0,0115 |
8136 0,9667 |
|||||
Таким образом, сравнение характеристик метода полиномов с алгоритмами распознавания символов другой природы показывает его конкурентоспособность в области генерации монотонных оценок и быстродействия, что делает возможным его использование в комбинированных алгоритмах распознавания символов.
5. Литература
[1] Гавриков
М.Б., Пестрякова Н.В. Метод полиномиальной регрессии в задачах распознавания
печатных и рукопечатных символов. Препринт ИПМ им. М.В.Келдыша РАН, 2004, №22.
[2] Sebestyen
G.S. Decision Making Processes in
Pattern Recognition,
[3] Nilson N. J. Learning Machines,
[4] Schürmann J. Polynomklassifikatoren,
Oldenbourg, München, 1977.
[5] Schürmann J. Pattern
Сlassification, John Wiley&Sons,
Inc., 1996.
[6] Albert
A.E. and
[7] Becker
D. and Schürmann J. Zur
verstärkten Berucksichtigung schlecht erkennbarer Zeichen in der
Lernstichprobe // Wissenschaftliche Berichte AEG-Telefunken 45, 1972, pp. 97 –
105.
[8] Pao
Y.-H. The Functional Link Net:
Basis for an Integrated Neural-Net Computing Environment // in Yoh-Han Pao
(ed.) Adaptive Pattern Recognition and Neural Networks, Addisson-Wesley,
[9] Franke
J. On the Functional Classifier, in
Association Francaise pour
[10] Арлазаров В.Л., Логинов А.С., Славин О.А. Характеристики программ оптического распознавания текста // Программирование № 3, 2002, с. 45 – 63
[11] Арлазаров
В.В., Постников В.В., Шоломов Д.Л. Cognitive Forms – система
массового ввода структурированных документов // Сборник трудов ИСА РАН «Управление информационными потоками», 2001, с.
35-46
[12] Мисюрев
А.В. Использование искусственных
нейронных сетей
для распознавания рукопечатных символов // Сборник трудов ИСА РАН «Интеллектуальные
технологии ввода и обработки информации»,
1998, с. 122-127
[13] Cлавин О.А.,
Корольков Г.В., Болотин П.В. Методы распознавания грубых объектов // Сборник трудов ИСА
РАН «Развитие безбумажных технологий в организациях», 1999, с. 290-311
[14] Barroso
J., Bulas-Cruz J., Rafael J., Dagless E. L. Identificação
Automática de Placas de Matrícula Automóveis // 4.as
Jornadas Luso-Espanholas de Engenharia Electrotécnica, Porto, Portugal,
Julho (1995), ISBN 972-752-004-9.
[15]
Дж.Себер. Линейный регрессионный анализ. М.:”Мир”, 1980.
[16]
Ю.В.Линник. Метод наименьших квадратов и основы математико -
статистической теории обработки наблюдений. М.:”Физматлит”, 1958.