Особенности применения метода частичных вычислений к специализации программ на
объектно-ориентированных языках
|
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
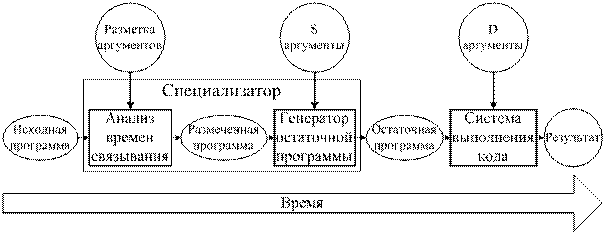
Рис.
1. Общепринятая структура специализатора,
основанного на методе частичных вычислений.
Часть метода специализации, отвечающая за разделение операций и данных, называется анализом времен связывания (Binding Time Analysis, BTA, BT-анализ) (рис. 1). Вторая часть метода специализации, отвечающая за вычисление статической части программы и выделение динамической части в отдельную программу, называется генератором остаточной программы (Residual Program Generator, RPG). В этой части, собственно, и происходят «частичные вычисления».
Для примера рассмотрим функцию возведения в степень, написанную на функциональном языке Haskell. И поставим задачу проспециализировать метод toPower по второму аргументу, равному 5.
Тогда мы считаем, что первый аргумент — динамический, а второй — статический, и строим разметку всей программы:
|
toPower :: Double -> Int -> Double toPower
x 0 = 1.0 toPower x n = x*(toPower x (n-1)) |
toPower :: DoubleD
-> IntS -> DoubleD toPower xD 0S =
1.0D toPower xD nS =
xD*D(toPowerS
xD (nS-S1S)) |
Рис.
2. Пример: исходная и размеченная программы
на функциональном языке.
Проведя генерацию остаточной программы, выполнив все S-действия и оставив D-действия, получаем:
|
toPower5
::
Double -> Double toPower5 x = x*x*x*x*x*1.0 |
Рис.
3. Пример: результат специализации программы
на функциональном языке.
В результате остаточная программа не содержит проверок показателя степени на равенство нулю и операции с этим показателем.
Аналогично можно провести специализацию и императивной программы возведения в степень. Разметка программы строится аналогично.
|
double toPower (double x, int n) { if
(n == 0) return
1.0; else return
x*toPower(x, n-1); } |
doubleD toPower (double xD,
int nS) { ifS (nS ==S 0S) returnD 1.0D; elseS returnD xD*DtoPowerS(xD, nS-S1S); } |
Рис. 4. Пример: исходная и размеченная программы на императивном языке.
В результате специализации останутся только операции с x:
|
double toPower5 (double x) { return
x*x*x*x*x*1.0; } |
Рис. 5. Пример: результат специализации программы на императивном языке.
Следует отметить, что BT-анализ и генератор остаточной программы могут работать как одновременно, так и по очереди: сначала анализ времен связывания, затем генератор остаточной программы. В первом случае мы получим так называемый online PE, во втором — offline PE. В дальнейшем мы будем говорить только об offline PE.
В offline частичном вычислителе сначала конструкции программы размечаются на статические (S) и динамические (D) с помощью анализа времен связывания. В процессе анализа могут быть выполнены некоторые преобразования программы для улучшения качества разметки (например, добавлены операции поднятия Lifting).
После этого генератор остаточной программы, используя частично заданные аргументы и размеченную программу, выполняет все статические операции, а все динамические операции переносит в остаточную программу. В результате получаем остаточную программу, зависящую только от аргументов, неизвестных во время специализации.
Далее подробно рассмотрим оба этапа offline частичных вычислений: анализ времен связывания и генерация остаточной программы.
3.  Определение
корректности специализатора (основное свойство специализатора)
Определение
корректности специализатора (основное свойство специализатора)
Рассмотрим программу f от переменных x,…,y,u,…,v и множество значений переменных D. Пусть значения аргументов x,…,y известны и равны x0,…,y0 Î D. Пусть в результате специализации программы f при известных значениях x0,…,y0 переменных x,…,y, получилась программа g, зависящая от переменных u,…,v, неизвестных во время генерации остаточной программы. Тогда для любых значений u1,…,v1 Î D переменных u,…,v результат вычисления программы f от значений x0,…,y0,u1,…,v1 и программы g от значений u1,…,v1 должны совпадать:
|
Если spec(f,x0,…,yo) = g, где x0,…,yo Î D то "u1,…,v1 Î D : f(x0,…,yo,u1,…,v1) = g(u1,…,v1) |
Рис. 6. Определение корректности специализации.
4. Анализ времен связывания
Цель анализа времен связывания — разделить программу на статическую и динамическую части. Такое разделение может быть произведено несколькими способами. Однако необходимо, чтобы статические операции в таком разделении всегда получали только статические данные, а операции, которые в каких-то случаях могут получить динамические данные, должны быть размечены как динамические.
Такое разделение, как правило, может быть выполнено различными способами. Можно даже все данные отнести к динамическим. И для любого способа остаточная программа будет получаться правильной (если разделение построено согласно описанным ниже правилам). Но чем больше операций будет отнесено к статическим, тем более эффективной будет остаточная программа.
Для разделения на статическую и динамическую части анализ времен связывания использует BT-разметку: разметку инструкций, элементов стека и переменных. Построенная разметка должна быть внутренне согласованной, удовлетворять правилам, которые будут описаны ниже: например, всякая статическая операция должна иметь статические аргументы, а динамическая — динамические. Статическое данное может стать аргументом динамической операции, если оно будет предварительно преобразовано специальной операцией поднятия Lifting. Обратный переход — из динамики в статику — невозможен.
Для достижения согласованности, помимо добавления операций поднятия, исходная программа может быть подвергнута и другим преобразованиям.
Возможно несколько вариантов реализации BT-анализа:
1. Моновариантный по переменным — каждую переменную разрешается разметить одним способом независимо от точки ее использования в программе.
2. Поливариантный по переменным — разрешается в разный частях программы размечать одну и ту же переменную по-разному. Это позволяет более эффективно производить специализацию кода, в котором одна и та же переменная используется в разных местах программы с разными целями.
3. Моновариантный по операциям — запрещается преобразовывать и размножать код внутри метода и, следовательно, приходится каждую операцию размечать только одним способом.
4. Поливариантный по операциям — можно преобразовывать и размножать код внутри метода, что позволяет одному участку кода исходной программы сопоставить несколько участков выходной размеченной программы с разными BT-разметками. Это позволяет более качественно разметить программу, но существует опасность многократного роста размера программы.
5. Моновариантный по методам — каждый метод размечается только одним способом. В этом случае все использования метода будут одинаково размечены, хотя метод мог использоваться в совершенно разных условиях (например, в одном случае все известно, в другом — ничего не известно)
6. Поливариантный по методам — каждый метод может быть размечен в зависимости от его использования — разметки аргументов и результатов в точке вызова. Также во время специализации некоторые методы целесообразно развернуть — подставить в место вызова тело метода (inline). В таких случаях программист должен добавить соответствующую аннотацию. Если метод не разворачивается, то это накладывает на его разметку дополнительные требования. А развертка метода может привести к увеличению программы и бесконечной работе специализатора.
7. Моновариантный по классам — каждый класс размечается только одним способом. В таком варианте все объекты данного класса будут одинаково проспециализированы, независимо от особенностей использования.
8. Поливариантный по классам — каждый класс может иметь несколько разметок. Это позволяет по-разному разметить различные использования объектов данного класса.
В итоге, анализ времен связывания по программе и начальной разметке, которая содержит разметку входных данных и, быть может, разметку других элементов, заданных пользователем, должен построить BT-разметку всех операций и используемых данных, удовлетворяющую правилам согласованной разметки в программе.
5. Генерация остаточной программы
После построения корректно размеченной программы, генератор остаточной программы, с помощью частичных вычислений, строит окончательный результат специализации: остаточную программу.
На вход генератору остаточной программы поступают размеченная программа и значения S-переменных. По этим данным он строит остаточную программу, зависящую только от части переменных — только от D-переменных, динамических исходных данных, неизвестных во время специализации программы.
Если разметка программы была построена согласованно, то генератор остаточной программы построит программу, которая будет эквивалентна исходной программе при указанных значениях S-переменных и всех значениях D-переменных. Это основное свойство генератора остаточной программы.
Генератор остаточной программы производит обобщенное выполнение программы: S-инструкции выполняются, а D-инструкции переходят в остаточную программу. Собственно на этом этапе выполняется часть операций, откуда и происходит термин «частичные вычисления».
В
процессе порождения остаточной программы генератор сравнивает состояния для
возможного построения циклов или рекурсии в остаточной программе. Но при некоторых
начальных данных, т.е. для некоторых программ и их разметок, генератор остаточной
программы может работать бесконечно долго, пытаясь построить остаточную программу.
Если работа генератора остаточной программы завершается, то получается остаточная программа эквивалентная исходной. Если в задании на частичные вычисления часть аргументов метода была статической, то в результате порождается новый метод, зависящий только от оставшихся динамических аргументов. И вызов метода необходимо вставить в остаточную программу.
Если же в задании на частичные вычисления все аргументы были динамическими, а частичные вычисления производились только по внутренним статическим данным, то в результате получаем метод, полностью эквивалентный исходному методу. Поэтому в остаточную программу вставляется эквивалентный метод (хотя, может быть, и оптимизированный).
6. Особенности объектно-ориентированных языков
Функциональные языки обладают множеством свойств, облегчающих анализ программ. К числу таких свойств можно отнести отсутствие побочных эффектов, отсутствие глобального состояния, передача аргументов и результатов по значению, и т.п.
Объектно-ориентированные языки не обладают этими удобными свойствами, поэтому при анализе и преобразовании программ приходится учитывать:
1. Наличие глобального изменяемого состояния (в функциональных языках такое состояние отсутствует).
2. Наличие ссылок на элементы (объекты) глобального состояния (которые в некоторых языках могут идентифицироваться по именам, известным во время компиляции программы).
3. Объекты могут состоять из полей (обращение к которым происходит по имени, известному во время компиляции), либо являться массивами (обращение к элементам которых происходит по номерам, неизвестным во время компиляции программы).
4. Передача аргументов и результатов по ссылке (в функциональных языках аргументы и результаты передаются по значению).
5. Представление программы в виде последовательности инструкций (а не в виде графа передачи данных).
6. Наличие конструкций передачи управления (цикл, goto).
7. Наличие конструкции наследования классов.
8. Наличие виртуальных методов.
7. Обзор существующих специализаторов для объектно-ориентированных языков
Существует много работ посвященных частичным вычислениям для функциональных языков [Jone93]. Одной из фундаментальных работ, посвященных методам частичных вычислений, является работа N.D. Jones, C.K. Gomard, P. Sestoft «Partial Evaluation and Automatic Program Generation» 1993г. [Jone93]. В ней в основном рассматриваются методы частичных вычислений для функциональных языков. Методам частичных вычислений для императивных языков посвящена всего одна глава — «Частичные вычисления для языка C».
Однако, имеется гораздо меньше работ по специализации и частичным вычислениям для языков с императивными особенностями, к рассмотрению которых мы и переходим.
7.1. Ламбда-исчисления с императивными конструкциями
Одним из направлений исследований частичных вычислителей для языков с императивными конструкциями является разработка частичного вычислителя для ламбда-исчисления с побочными эффектами, выполненная Кенити Асаи (Kenichi Asai) из университета города Токио [Asai97]. В представленном ламбда-исчислении присутствуют операции для изменения значения выражения. В работе предложен алгоритм разделения данных на изменяемые и неизменяемые и построен частичный вычислитель, использующий такое разделение. В нем обращения к потенциально изменяемым данным переходят в остаточную программу.
Вторым направлением работ К. Асаи — разработка частичного вычислителя для ламбда-исчисления, способного одновременно генерировать код для вычисления выражения и вычислять это выражение [Asai99]. Такая возможность используется для преобразования данных из статических в динамические: в момент преобразования выражение строится не сразу, а постепенно, и его части могут использоваться для преобразования других данных из статических в динамические.
Третьим направлением работ группы под руководством К. Асаи является создание частичного вычислителя для ламбда-исчисления с продолжениями (continuations) [Asai02].
Разработанные К. Асаи методы расширяют возможности классического метода частичных вычислений, делая его применимым к ламбда-исчислению с побочными эффектами. Этого все же недостаточно для применения этого метода к объектно-ориентированным языкам.
7.2. Специализаторы для языка C
Первыми работами по созданию специализаторов для императивных языков являются работы по созданию специализатора для языка C. Однако язык C сложен для автоматического анализа: его семантика не всегда достаточно прозрачна. Также трудности связаны со структурой данных, с которыми он работает: фактически вся память представляет собой один большой массив, из-за чего затруднительно реализовать достаточное для практических задач разделение данных на статические и динамические.
Также и сами программы на языке C обычно пишутся в сложном для анализа стиле: сам язык провоцирует программиста писать программы в таком стиле, который затрудняет автоматический анализ программ.
C-Mix
Еще в начале 90х готов Ларс Оле Андерсен (Lars Ole Andersen) в университете Копенгагена в Дании разработал [Ande91,Ande93,Ande94] специализатор С-MIX для языка C.
Специализация программы на языке C проводится в несколько этапов:
1. Первый этап — анализ ссылок. Для каждой переменной-ссылки строится множество переменных и областей памяти, на которые она может ссылаться. Если несколько ссылок-переменных в результате анализа могут ссылаться на одно и то же, то они должны быть размечены одинаково.
2. Второй этап — построение разметки времен связывания. Ссылки на одно и то же должны быть размечены одинаково.
3. Третий этап — генерация остаточной программы.
Tempo
В результате развития идей, заложенных в C-Mix, группой Шарля Консула (Charles Consel), Джулии Лавалла (Julia L. Lawall) (Университет города Копенгагена, Франция), Анне Франкойсе Ле Мур (Anne-Francoise Le Meur) в лаборатории исследований информатики и вычислительной техники в Бордо во Франции был создан специализатор Tempo [Cons03]. Это специализатор для языка C, во многом аналогичный C-Mix.
7.3. Специализация для байт-кода Явы
Работы в университете города Токио
В университете города Токио под руководством Акинори Ёнэдзава (Akinori Yonezawa) и Хидэхико Масусяра (Hidehiko Masushara) разрабатывается специализатор для байт-кода Явы, который можно было бы встроить в JIT-компилятор байт-кода.
Описанный в работе [Masu99] специализатор обрабатывает только примитивные данные и статические методы. Допускается различная разметка переменных в различных точках программы. В работе показано, как для метода построить систему ограничений на разметку локальных переменных и инструкций.
В поздней работе [Affe02] группой Рефналд Аффелдт (Reynald Affeldt), Хидэхико Масусяра (Hidehiko Masushara), Эйдзиро Сумми (Eijiro Summi), Акинори Ёнэдзава (Akinori Yonezawa) предложено расширение специализатора, позволяющее обрабатывать и объекты. Разметка переменных описывается деревьями: S или D в вершине дерева определяет статический или динамический объект будет находиться в этой переменной, а поддеревья определяют разметку полей объекта.
Анализ метода основан на разделении объектов на локальные объекты (которые создаются внутри этого метода) и нелокальные (которые передаются методу извне).
Локальные объекты делятся на те, которые могут быть выданы в качестве результата работы метода, и те, которые используются только внутри метода. Нелокальные объекты разделяются на те, в поля которых может осуществляться присваивание, и те, в поля которых присваивание не происходит. Инструкции создания локальных объектов, которые могут быть выданы, и присваивания в поля нелокальных объектов обязаны размечаться динамически и переходить в остаточную программу.
После разделения строится разметка всех инструкций в программе.
В обеих работах [Masu99,Affe02] описаны специализаторы времени исполнения (run-time specialization). По построенной разметке строится метапрограмма: программа, генерирующая результат специализации по известным значениям статических аргументов. Во время выполнения остаточной программы, сначала по статической части аргументов строится специализированная версия метода, а затем эта специализированная версия метода выполняется.
Работы П. Бертелсена
В королевском ветеринарно-земледельческом университете (Royal Veterinary and Agriculture University) в городе Копенгагене в Дании Питер Бертелсен (Peter Bertelsen) занимался семантикой и анализом времен связывания Ява программ.
В своей работе [Bert99] П. Бертелсен рассматривает подмножество байт-кода Явы. Это подмножество содержит инструкции для работы с локальными переменными, операции на стеке с примитивными данными и массивами и инструкции перехода Goto и If. Инструкций вызовов методов и возможность создания объектов нет.
В работе описаны допустимые разметки и ограничения на корректную разметку программы, и предложен метод нахождения решения для системы ограничений.
Описан генератор остаточной программы, который по размеченной программе и значениям статических аргументов строит остаточную программу.
Работы У.П. Шульца
В университете города Реннес (Rennes) во Франции Ульрик Пагх Шульц (Ulrik Pagh Schultz) в рамках своей диссертации разработал частичный вычислитель для подмножества байт-кода Ява [Schu00,Schu03].
Описанное подмножество относительно широко: можно описывать классы, конструкторы и методы. Разрешены операции над примитивными данным и виртуальные вызовы.
Но отсутствуют операции работы с массивами, возможность изменять значения полей объектов, тело метода представляется не в виде последовательности инструкций, а в виде одного выражения.
Как и в предыдущих работах, программе сопоставляется система ограничений на разметку. Но в отличие от них, разметка строится для описаний классов, а не для переменных в программе. Разметка программы строится путем решения системы ограничений.
На основе размеченной программы генератором остаточной программы по известным значениям статических переменных строится остаточная программа.
В следующих главах У.П. Шульц описывает усовершенствования, которые необходимы для работы с реальными программами:
1. class polyvariance — класс размечается несколькими способами и каждому new соответствует одна из разметок;
2. method polyvariance — для каждого вызова метода метод размечается отдельно;
3. alias polyvariance — анализ, помечающий где могут быть одинаковые данные, а где — разные. Желательно, чтобы и alias analysis был поливариантным (размножал классы и методы).
Однако математического аппарата для реализации такого рода усовершенствований не предлагается.
7.4. Выводы
Можно сделать вывод, что в рассмотренных выше работах предложены различные методы частичных вычислений для подмножеств объектно-ориентированного языка Ява. При этом, в каждом из этих подмножеств наложены такие сильные ограничения, которые обычно не выполняются для реальных программ на языке Ява.
|
|
Инструкции передачи |
Работа с |
|
|
массивами |
объектами |
||
|
Х. Масусяра |
да |
нет |
да |
|
П. Бертелсен |
да |
да |
нет |
|
У.П. Шульц |
нет |
нет |
да |
Рис. 7. Классификация специализаторов на базе метода
частичных
вычислений по полноте реализации объектно-ориентированного языка.
|
|
Поливариантность по |
|||
|
Переменным |
инструкциям |
методам |
классам / массивам |
|
|
Х. Масусяра |
да |
нет |
нет |
да |
|
П. Бертелсен |
да |
нет |
нет |
да |
|
У.П. Шульц |
нет |
нет |
нет |
нет |
Рис. 8. Классификация специализаторов на базе метода
частичных вычислений по поливариантности.
Для практических применений к объектно-ориентированным языкам метод частичных вычислений должен:
1. Обрабатывать инструкции передачи управления Goto и If.
2. Поддерживать работу с объектами и массивами, допускать возможность изменения полей объектов и элементов массива.
3. Обладать единым анализом времен связывания (не проводить отдельный alias analysis).
4. Обладать поливариантностью по переменным (допускать несколько различных разметок одной и той же переменной в различных точках программы).
5. Обладать поливариантностью по инструкциям (допускать несколько различных разметок частей метода в зависимости от разметки переменных и стека).
6. Обладать поливариантностью по методам (допускать несколько различных разметок метода в зависимости от разметки аргументов и результатов метода).
7. Обладать поливариантностью по классам и массивам (допускать несколько различных разметок однотипных переменных).
8. Обладать расширенной разметкой объектов и массивов: одни поля статических объектов могут иметь статическую разметку, в то время как другие поля — динамическую.
8.
Пример
Следующий пример взят из книги Refactoring to Patterns [Keri04] глава «Replace Implicit Language with
Interpreter».
Допустим, что имеется набор объектов таких, что каждый объект обладает каким-нибудь набором свойств. И нужно отбирать объекты по этим свойствам с помощью каких-нибудь критериев.
Например, свойством объекта может быть значение целочисленного поля объекта, и нужно отобрать те объекты, у которых значение этого поля лежит в заданном интервале.
Обычное решение такой проблемы заключается в написании метода, в цикле проверяющего свойства каждого объекта. Но если нужно отбирать объекты по разным логическим условиям, то в программе возникает много методов, тела которых очень похожи: в каждом из методов требуется «прокручивать» цикл по всем объектам.
Структуру программы можно улучшить, вынеся общие части многих методов в один метод, который принимает на вход предикат, представленный в виде объекта и описывающий логическое условие, по которому следует провести поиск. Таким образом, цикл, проходящий по всем объектам и применяющий предикат к каждому объекту, появляется в теле только одного метода.
Часто бывает нужно не только построить несколько предикатов, но и уметь их комбинировать с помощью логический операций И, ИЛИ, НЕ. Тогда можно реализовать не только объекты-предикаты, но и объекты-операции.
В [Keri04] рассмотрен следующий пример (рис. 9). Имеется класс Product для описания продуктов, имеющий два поля-критерия: цвет и цена. И есть абстрактный класс Spec с виртуальным методом-предикатом IsSatisfiedBy(Product) для описания предикатов. Описаны два объекта-предиката ColorSpec и BelowPriceSpec — для поиска товара по цвету и по цене. А также два объекта-операции AndSpec и NotSpec (для взятия логического И и НЕ для предикатов). Тогда, чтобы найти все товары с цветом, отличным от заданного, и ценой, менее заданной, достаточно создать следующий объект: new AndSpec(new BelowPriceSpec(price), new NotSpec(new ColorSpec(color))).
class Product { public int color; public double price; public
Product (int color, double
price) { this.color = color; this.price
= price; } } abstract class Spec { [Inline] public Spec () {} [Inline] public abstract
bool IsSatisfiedBy (Product product); } class AndSpec : Spec { Spec x, y; [Inline] public AndSpec (Spec x, Spec y) { this.x = x; this.y = y; } [Inline] public override
bool IsSatisfiedBy (Product product) { return this.x.IsSatisfiedBy(product)
&& this.y.IsSatisfiedBy(product); } } class NotSpec : Spec { Spec x; [Inline] public NotSpec (Spec x) { this.x = x; } [Inline] public override
bool IsSatisfiedBy (Product product) { return ! this.x.IsSatisfiedBy(product); } } class ColorSpec : Spec
{ int color; [Inline] public
ColorSpec (int color) { this.color
= color; } [Inline] public override
bool IsSatisfiedBy (Product product) { return
product.color == this.color; } } class BelowPriceSpec :
Spec { double price; [Inline] public
BelowPriceSpec (double price) { this.price = price; } [Inline] public override
bool IsSatisfiedBy (Product product) { return
product.price < this.price; } } class ProductFinder { IEnumerable repository; public
ProductFinder (IEnumerable repository) {
this.repository
= repository; } [Inline] public IList SelectBy (Spec spec) { IList foundProducts = new ArrayList(); IEnumerator products = this.repository.GetEnumerator(); while (products.MoveNext()) { Product product =
(Product) products.Current; if (spec.IsSatisfiedBy(product))
foundProducts.Add(product); } return foundProducts; } [Specialize] public
IList BelowPriceAvoidingAColor (double price, int color) { Spec spec = new AndSpec(new BelowPriceSpec(price), new
NotSpec( new
ColorSpec(color))); return SelectBy(spec); } } |
Рис. 9. Исходная программа
Такой способ более удобен для чтения, анализа и преобразования программы. Но такая программа может работать менее эффективно, чем вариант с явными проверками полей объектов, поскольку при каждой проверке истинности предиката происходит обход дерева объектов, описывающих предикат. Т.е., вычисление предиката происходит «в режиме интерпретации».
Для получения эффективной программы в данном случае уместно использовать методы специализации. Частичный вычислитель для объектно-ориентированных языков должен уметь специализировать такого рода программы, убирая создание и использование временных объектов, создание и использование которых полностью прослеживается в период специализации.
В данном примере, частичный вычислитель, удовлетворяющий требованиям, сформулированным в разделе 7.4, уберет создание «лишних» объектов AndSpec, BelowPriceSpec, NotSpec и ColorSpec, а в том месте, где был вызов метода IsSatisfiedBy, поставит явную проверку полей объекта (рис. 10).
|
class Product { public int color; public double price; public
Product (int color, double
price) { this.color = color; this.price
= price; } } class ProductFinder { IEnumerable repository; public
ProductFinder (IEnumerable repository)
{ this.repository
= repository; } public
IList BelowPriceAvoidingAColor (double price, int color) { IList foundProducts = new ArrayList(); IEnumerator products = this.repository.GetEnumerator(); while (products.MoveNext()) { Product product =
(Product) products.Current; if (product.price<price && !(product.color==color))
foundProducts.Add(product); } return foundProducts; } } |
Рис. 10. Результат специализации.
Данный пример показывает, что методы специализации позволяют использовать высокоуровневые методы программирования без потери эффективности.
9. Заключение
В работе рассмотрены существующие в данный момент специализаторы, основанные на методе частичных вычислений и применимые к программам, написанным на императивных и объектно-ориентированных языках. По этим работам видно, что полноценного специализатора для объектно-ориентированных языков типа Ява или C# , применимого к реалистичным программам, пока не создано. Однако большая практическая важность таких языков требует создания подобных специализаторов.
В работах автора [Chep03,Klim05a,Klim05b,Klim06] описаны основные принципы, на которых основан специализатор для объектно-ориентированного языка, близкого к Яве и C#, который обладает всеми существенными возможностями, присущими языкам Ява и C#, что позволяет непосредственно применить разработанные методы для специализации внутреннего языка платформы Microsoft.NET [Chep03].
10. Литература
[Affe02] R.Affeldt,
H.Masuhara, E.Sumii, A. Yonezawa "Supporting objects in run-time bytecode
specialization" // In Proceedings of the ASIAN symposium on Partial
evaluation and semantics-based program manipulation, pages 50-60. ACM Press,
2002.
[Ande91] L.O.Andersen
"C program specialization" // Master’s thesis, DIKU, University of
Copenhagen, Denmark, December 1991. DIKU Student Project 91-12-17, 134 pages.
[Ande93] L.O.Andersen
"Partial Evaluation of C" // chapter
[Ande94] L.O.Andersen
"Program Analysis and Specialization for the C Programming Language"
// PhD thesis, Computer Science Department, University of Copenhagen, May 1994.
DIKU Technical Report 94/19.
[Asai97] K.Asai,
H.Masuhara, A.Yonezawa "Partial evaluation of callbyvalue
lambdacalculus with sideeffects" // In Charles Consel, editor, Proc. ACM
SIGPLAN Symposium on Partial Evaluation and SemanticsBased Program Manipulation
PEPM '97, pages 12--21, Amsterdam, The Netherlands, June 1997. ACM Press.
[Asai99] K.
Asai, Binding-time analysis for both static and dynamic expressions. In A. Cortesi
and G. File, editors, Static Analysis Symposium, volume 1694 of Lecture Notes
in Computer Science, pages 117—133. Springer-Verlag, 1999.
[Asai02] K.
Asai, Offline Partial Evaluation for Shift and Reset. ACM SIGPLAN Symposium on
Partial Evaluation and Semantics-Based Program Manipulation (PEPM '04), pp.3-14
(August 2004).
[Bert99] P.Bertelsen
"Binding-time analysis for a JVM core language" // April 1999. Unpublished
note; available from http://www.dina.kvl.dk/~pmb.
[Schu00] U.P.Schultz
"Object-Oriented Software Engineering Using Partial Evaluation" //
PhD thesis, University of Rennes I, Rennes, France, December 2000.
[Chep03] A.M.Chepovsky,
A.V.Klimov, A.V.Klimov, Y.A.Klimov, A.S.Mishchenko, S.A.Romanenko,
S.Y.Skorobogatov "Partial Evaluation for Common Intermediate
Language" // Manfred Broy and Alexandre V. Zamulin (eds.), Perspectives of
Systems Informatics, 5th International Andrei Ershov Memorial Conference,
PSI'2003, Akademgorodok, Novosibirsk, Russia, July 9-12, 2003. LNCS 2890,
Springer-Verlag, December 2003, pp.171-177
[Cons03] C.Consel,
J.L.Lawall, A.-F.Le Meur "A Tour of Tempo A Program Specializer for the C
Language" // 2003
[Jone93] N.D.
Jones, C.K. Gomard, P. Sestoft // "Partial Evaluation and Automatic Compiler
Generation" // C.A.R. Hoare Series, Prentice-Hall, 1993
[Keri04] J.Kerievsky
"Refactoring to Patterns" // Addison Wesley, August 05, 2004
[Klim05a] Ю.А.Климов
"Поливариантный анализ времен связывания в специализаторе CILPE для Common Intermediate
Language
платформы Microsoft.NET" // Труды Всероссийской
конференции "Технологии Microsoft
в теории и практике программирования", Москва, 17-18 февраля
[Klim05b] Ю.А.Климов
"О поливариантном анализе времен связывания в специализаторе
объектно-ориентированного языка" // Труды Всероссийской научной
конференции "Научный сервис в сети ИНТЕРНЕТ: технологии распределенных
вычислений", Новороссийск, 19-24 сентября
[Klim06] Ю.А.Климов "Генератор остаточной программы и
корректность специализатора объектно-ориентированного языка" // Труды Всероссийской
научной конференции "Научный сервис в сети ИНТЕРНЕТ: технологии параллельного
программирования", Новороссийск, 18-23 сентября
[Masu99] H.Masuhara,
A.Yonezawa "Run-time Program Specialization in Java Bytecode" // In Proceedings
of the JSSST SIGOOC 1999 Workshop on Systems for Programming and Applications
(SPA'99), March 1999.
[Schu03] U.P.Schultz,
J.L.Lawall, C.Consel "Automatic program specialization for Java" //
ACM Transactions on Programming Languages and Systems 25 (4) (2003) 452-499.